Technical Resources
Educational Resources
APM Integrated Experience
Connect with Us
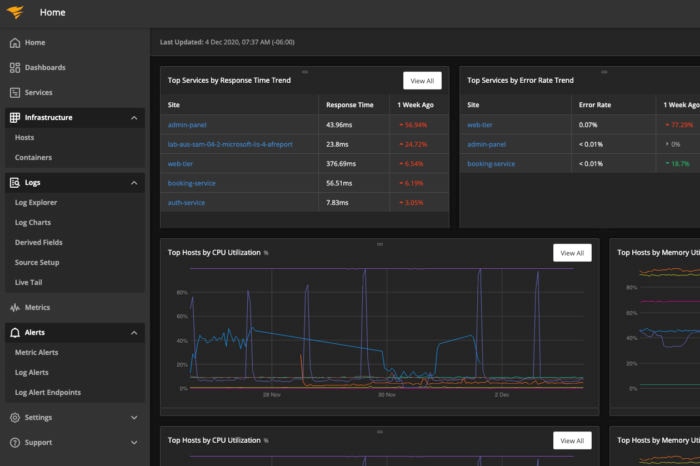
Get relevant context, data, and visualizations to help you rapidly get to the root of a problem and fix it with a single, easy-to-use product experience.
Quickly pinpoint the root cause of performance issues across the stack—down to a poor-performing line of code—by monitoring trace, metric, log, and user data all within a single platform.
Whether a problem is client side or server side, teams can work together to solve performance issues and keep applications running as they should.
Get up and running in minutes with functionalities and simple visualizations that don’t require intimate knowledge of the application code to get to rapid results.
Get a continuous and proactive view of performance across applications, services, and infrastructure down to the request level and eliminate issues before they affect users or cause service interruptions. Use interactive dashboards to analyze and visualize your log data and connect the dots with a unified view. Let our powerful, interactive search help with fast troubleshooting and lower mean time to resolution.
Get highly scalable, cost-effective infrastructure monitoring and troubleshooting with a tool designed to make APM easier. Monitor the health of your critical systems so you can know the moment there’s an issue. With our proactive, advanced alerting, you can jump right into the distributed tracing, live code profiling, and exception tracking to drill all the way down to the poor-performing line of code.
Our easy and affordable end-user experience monitoring brings you ultimate visibility and troubleshooting. With synthetic monitoring, you’ll know when critical pages or flows stop working correctly through uptime monitoring, page speed analysis, and transaction monitoring. With RUM, you get visibility into how actual end users are interacting with and experiencing your website.
“Before Pingdom®, we had to find out when a client site was down by going to the site or if a client contacted us about it. This tool allows us to be much more proactive and react as soon as we get a notification that there is downtime.”
Client Service Lead
SVM E-Marketing Solutions
“We’re also seeing value in how [AppOptics™, Pingdom, and Loggly®] can be integrated together. The interoperability between the systems allows us to get to the root of our problem faster and deliver our service better.”
CTO
Traxo
“AppOptics has become the cornerstone for discovering latency improvement steps on my team.”
Team Lead in Engineering
Marketing and Advertising Company