Technical Resources
Educational Resources
APM Integrated Experience
Connect with Us
Distributed systems offer many advantages, such as improved scalability and availability, but they can also be more challenging to manage. As an IT professional, you are responsible for keeping distributed systems running smoothly and efficiently. To do this, you need to monitor distributed systems effectively. This guide introduces the essential concepts of distributed systems monitoring and what you need to know to monitor one effectively. It covers identifying key performance indicators (KPIs), understanding system behavior, and best practices for distributed systems monitoring.
This essential guide will better equip you to monitor your distributed systems effectively and help keep them running smoothly. Understanding key concepts such as KPIs and system behavior will enable you to detect issues before they cause serious problems.
You need to monitor distributed systems ensuring every stakeholder will know how they’re doing. Distributed systems are complex, often consisting of many components working together to function correctly. It can therefore make monitoring these systems a challenge. To effectively monitor a distributed system, understanding the various components and how they work together is vital.
One of the critical concepts in distributed systems monitoring is identifying key performance indicators. These are measurements that track a system’s health and measure its performance. Understanding system behavior involves understanding how the system works and how its components interact. This knowledge can help you detect issues.
A distributed system is a system in which the components are distributed across multiple physical or logical locations.
The hardware of a distributed system can be divided into two categories: physical and virtual. Physical hardware includes servers, storage, and networking equipment. Virtual hardware is software that simulates physical hardware, including virtual machines and cloud instances.
The physical and virtual hardware of a distributed system can be divided further into the following categories:
The software of a distributed system can be divided into the following categories:
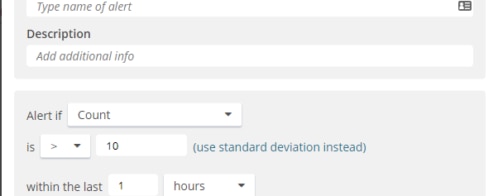
There are a few essential metrics to track when monitoring a component of a distributed system:
There are two main types of distributed systems monitoring: application-level monitoring and infrastructure-level monitoring. Both types are crucial for effectively managing a distributed system.
Application-level monitoring focuses on the performance of the system’s software. You can use this type of monitoring to detect issues such as slow response times or errors.
Infrastructure-level monitoring focuses on the hardware and software. You can use this type of monitoring to detect issues such as overloaded servers or network latency. You can also perform different types of monitoring on a distributed system. You can monitor the hardware, software, and networks. Monitoring the hardware means ensuring the system’s physical components are working correctly. It includes things like servers, storage devices, and other equipment.
Monitoring the software means making sure the application is working correctly. It includes databases, web servers, and other types of software.
Once you’ve decided to implement distributed systems monitoring, there are a few steps you need to take.
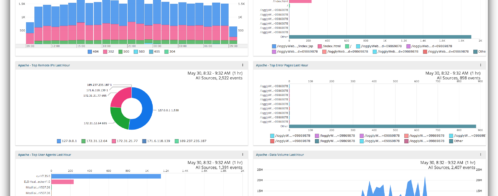
Logging is a type of data collection you can use for distributed systems monitoring. Logs can contain information about system events, such as when a user logs in or an error occurs. This information can help you understand system behavior and detect issues.
There are two main types of logs: system logs and application logs. The operating system generates system logs that contain information about system events. An important distinction to remember is software generates application logs. You can use both types in distributed systems monitoring. System logs can detect issues such as system errors or resource utilization. Application logs can detect issues such as application errors or slow response times.
Logging is a valuable tool for distributed systems monitoring, but it can be challenging to collect and manage log data. Log data can be voluminous, and it can be challenging to extract useful information from it.
Below is a list of capabilities logging provides to assist with efficiently running distributed systems:
There are a few things you can do to make logging easier.
Keeping a distributed system operational requires constant monitoring. IT professionals can identify issues before they become problems using KPIs and tracking system behavior. This ensures the system continues to operate smoothly. Loggly® provides log management and analytics platforms to help IT professionals troubleshoot and optimize their distributed systems. It comes with a free thirty-day trial.
This post was written by Tarun Telang. Tarun is a software engineering leader with over 16 years of experience in the software industry with some of the world’s most renowned software development firms like Microsoft, Oracle, BlackBerry, and SAP. His areas of expertise include Java, web, mobile, and cloud. He’s also experienced in managing software projects using Agile and Test Driven Development methodologies.
Didn’t find what you were after? Consider the SolarWinds Network Monitoring