Technical Resources
Educational Resources
APM Integrated Experience
Connect with Us
Most software engineers—or IT pros in general—would agree improving an app’s performance is a good thing. Also, most engineers have at least some understanding of best practices or techniques they can use to ensure better performance when writing code. It’s essential to carefully analyze an application both in development and in production and use the knowledge obtained to detect and fix performance problems, before releasing into production or when an error occurs after release. That, in a simplified manner, is what application performance monitoring (APM) is about. In this post, we’ll cover what APM is and how you can get started with it.
Before talking about the solution, let’s make sure we’re on the same page when it comes to the problem. We’ll do so by talking about application performance and why it matters. After that, we’ll be ready to tackle the solution. We’ll define APM, talk about its benefits, and explain how it works.
Finally, before wrapping up, we’ll share some tips on how to get started with APM in your organization. Let’s dig in.
Application performance monitoring can help you improve the performance of your apps and diagnose performance issues. But why is application performance so vital? Why should we care so much about improving it?
Companies compete every day, and technology has never been as integral to the success of businesses as it is today. A poor implementation of an application can have devastating impact to a company’s business. When it comes to web and mobile apps, the competition is always only a few clicks—or taps—away. Annoy your customers with a poor user experience, and you’ll be begging them to become former customers.
Not surprisingly, application performance plays a vital role in the overall user experience. It’s not hard to find articles showing users are getting more and more impatient with slowness in webpages. By adopting APM, organizations can improve the performance of their apps, ensuring their customers can enjoy the best user experience possible.
As if user experience concerns weren’t already bad enough, performance problems might have further developments. Performance issues might indicate deeper and more serious problems with the application.
For instance, poor performance might be caused by a memory leak or be evidence of potential security issues—more on this later.
We’ve briefly covered the problem application performance monitoring (APM) is supposed to solve: less-than-stellar performance in applications. Now that we’re on the same page when it comes to the problem, let’s cover the solution—application performance monitoring to the rescue!
APM refers to the process of using specialized tools to monitor applications in real time to understand how they behave and perform. By monitoring the experience of end users and tracking the behavior of applications, organizations can identify problems, obtain insights, and become better prepared to make decisions when it comes to code optimization.
Why should you care about APM? Well, the first main benefit of APM is to help the organization’s bottom line. Since APM contributes to an improved performance, it also contributes to better user experience.
In a nutshell, APM works by comparing how applications behave with how they should behave. When those two don’t match, it’s essential for your APM tool to gather information about the problem and notify relevant personnel, so the problem can be solved ASAP.
There are several different categories of information a comprehensive APM strategy should encompass, including metrics, traces, logs, and user experience.
Metrics are measurements you can track to monitor trends over a time. Time-series metrics such as CPU and memory use can give you a high-level view of the health and status of your infrastructure. Application metrics such as error rate and volume of requests can also give you valuable information.
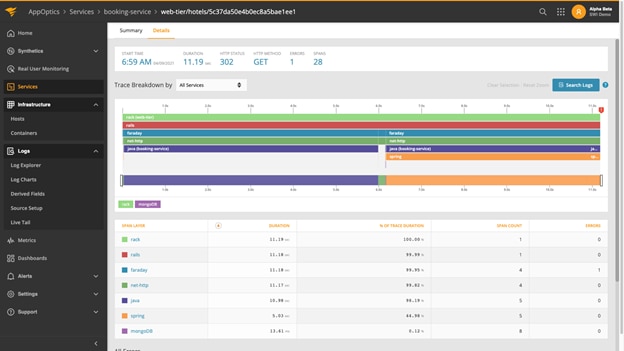
Traces are detailed accounts of how a specific request traveled through the system. A trace can span many services and show detailed information about each one of them. A transaction trace enables you to break down a request, making it easy to understand how much time is taken up by each layer of the transaction. When there are performance problems, traces help you identify what layer of the transaction is taking up the most time.
Logs are another piece of the puzzle. Engineers add logging when writing code as a means of making debug easier when the application misbehaves. Detailed logging can be tremendously valuable in helping organizations uncover the cause of a problem, especially when they contain detailed information—i.e., the stack trace—of exceptions.
User experience benefits from all components of the APM strategy. However, it can be more directly gauged by adopting monitoring strategies that evaluate the application’s performance from the end user’s point of view.
Using an integrated strategy, like the SolarWinds® APM Integrated Experience that combines metrics, traces, logs, and end user data (AppOptics™, Loggly®, and Pingdom®) allows you to combine server-side and client-side monitoring. For example, if you get alerted by a Pingdom synthetic transaction test about a booking application failing to complete, you then go into AppOptics and troubleshoot the booking service and realize the number of database queries was extremely high. You then perform a single click into the associated logs in Loggly, where you see that because there were so many calls, the booking service timed out before it could complete. You’ve used all three elements of the SolarWinds APM Integrated Experience to quickly identify an issue you can fix, hopefully before it caused any impact to users.
Up until now, we mainly covered the fundamentals of APM. We’ve explained what it is and what its benefits are. Then, we detailed some of its main components. Now, it’s time to share some practical steps you can take to get started with APM.
The term “application performance monitoring” can be misleading. People might assume APM is all about the code, or at least mostly about the code. And although some tools can certainly take this approach, it’s not what we recommend.
Instead, we suggest you adopt an integrated APM strategy. By adopting SolarWinds solutions, you get access to a centralized dashboard that brings logs, traces, metrics, and user data into a single view, giving you unprecedented visibility.
A plethora of APM tools are at your disposal. You must evaluate which tools are best for your organization’s needs. We encourage you to give Loggly a try, as well as the other solutions in the SolarWinds family.
Implementing an APM strategy can’t be an isolated initiative. Instead, the organization needs to ensure all relevant parties are onboard and understand the initiative. This is essential to obtain the necessary collaboration from all organizations.
For instance, having a APM tool that brings logs into its dashboard might not bring the expected results if engineers are unaware or unwilling to adopt logging best practices. So, make sure all actors understand and are willing to collaborate on the APM effort before it begins.
With all the pieces on the board, it’s time to start the match. Begin implementing your APM strategy using the chosen tools and metrics. With time, the organization will start to identify shortcomings and limitations with their approach. That’s perfectly natural. You just have to be sure those limitations aren’t an end in themselves, but a step into a better and improved approach.
This post covered the fundamentals of APM, how it works, and how to get started. It’s better to have a comprehensive approach to APM that considers not only infrastructure metrics but also logs and traces. This gives you visibility into all layers of your system, meaning your ability to detect and fix problems will be unprecedented.
Thanks for reading, and until next time, happy monitoring!
This post was written by Carlos Schults. Carlos is a consultant and software engineer with experience in desktop, web, and mobile development. Though his primary language is C#, he has experience with a number of languages and platforms. His main interests include automated testing, version control, and code quality.
Didn’t find what you were after? Consider the SolarWinds DevOps monitoring Tool