Confessions of a Logging Fanboy
I love podcasts.
Really, I love them. I love to learn from some of the best mentors and life hackers from pretty much all over the world. The only problem with me and podcasts is that they get me behind work-wise since I always have plenty to do and there’s so much excellent content out there.
So last night, while I was packing up things for my 200-mile trip – I am currently writing this from a train from Lisboa to Porto in Portugal – I was listening to this amazing podcast by Tim Ferriss where he interviews biz angel Chris Sacca, a VC rockstar who was on the cover of Forbes last April.
Two pieces of information caught my attention:
- Chris passed on investing in a certain Internet startup that offers a BOX where you can actually DROP files and stuff because back then he was at Google working on something that would be eventually rolled out as “GDrive” (and that he was quite sure would kill every other competitor in the market).
- Same thing happened with another startup in its early stages of investment, one that would eventually be known for some BNB services over the AIR, simply because he felt, given the fact that you could try to rent a room in a flat where the owner could still live there, that (I quote), “Someone was going to get raped or murdered and the blood would be on your [the founders’] hands.”
Just to show that even if you are the best at what you do, there is always something elusive that may go under your radar. So when we talk about software development, what do you think it is the best way to minimize damage when doing a product rollout?
During my 21 years of work in the wonderful world of information technology, the last 13 have been spent developing videogames. In the videogame realm, you need strong skills that broad enough so that nothing remains impossible. You need to know about computer graphics, artificial intelligence, networks, client-server development, many languages and paradigms, and how to explain things to Muggles (non-programming folks) so that your artists can deliver the best results without compromising performance. And, the biggest hurdle of them all: Liaising with stakeholders.
I have shipped products that were on both ends of the scale when it comes down to KPI measurable success. In terms of milestone achievements, the biggest product that I helped to deliver was one that currently has more than 10 million daily active users. That’s like every single inhabitant of Portugal, my birth country, playing that game every single day. When you deliver products in such a wide scale, you get to learn a lot, and one of things I learned in my career is that logging is great.
And why is that? Because if you care for your logs, they can be your best friends (well, it would be sad if logs were your friends, so please try to socialize a little); if you do not pay much attention to them, they may end up biting you in the… well, you know where, hopefully.
Here are some examples of situations I experienced where logging helped me a lot, and also where I learned a lot from it.
Educational Logging Moment #1: Got Disconnect?
There was once this mobile game. Let us call it Log Mayhem. Log Mayhem was a huge success right from launch. Retention rates were great, and both the install base and DAU counts were skyrocketing. And yes, we monitored logs.
During one of the updates, we successfully deployed the build to all relevant app stores, waited for propagation, tested the production build, and all seemed fine. But it was not. Something that we overlooked and passed right through QA would become a massive issue, and it did. Users were getting disconnected from the server after 15 minutes of the session’s start.
Everything would have been fine if we’d had the proper parameters in place. We were monitoring session connections, disconnects, and logins. Everything seemed fine with nothing going below the normality threshold. Just a tiny spike in logins, but nothing major. Yet!
By the time things were getting out of hand, it was late at night and no one was in the office. But we were not worried since we had alarms to be triggered whenever something went wrong. But no alarms rang and we all slept perfectly well.
The next morning Customer Service was going crazy with complaints from all the dissatisfied users, especially from those who were trying to get some decent play time during our night time, and were constantly getting disconnected after 15 minutes.
Now let me pause for a moment. We all know (hopefully) about the importance of proper logging and instrumentation. That is a solid fact that even a programmer fresh out of college knows (again, hopefully). It has been like this since what, for me, now seems like a lifetime.
I still remember my pre-videogame days, when I developed IDS (intrusion detection systems) and often did forensic analysis on cyber attacks. Word on the street was that logs were our only friends in the process (well, again, most of us had real friends). I relied on the valuable information that, whenever possible (yes, many people loved to delete logs to remove any footprints from their “break-ins”), would provide many answers to our questions, or at the very least make us ask more questions.
As such, please trust me when I say that, in our more recent Log Mayhem example, we did in fact have proper logging in place.
So back to our game. I arrived at the office and was immediately assaulted by the CS Team Lead who asked what the f*ck was going on. I read the reports and tickets, ignored the stakeholder’s yelling, and went straight to the development team to try to figure out what was going on and why no one was called to work during the night.
By then I had realized that no alarms had been triggered, and were it not for the CS information, by simply looking at the live charts, it could have been just like another day, “business as usual.”
But it was not!
Why were the users being disconnected after 15 minutes? There were some theories on the table. But most importantly: why did everything seem normal in terms of log monitoring tools?
After awhile, we discovered why users were constantly being disconnected. A new server version had been rolled out as well to cope with the client changes, and apparently there was a faulty protocol implementation that made the server believe that the client had disconnected, as the latter was ignoring a request made by the server, a request that was part of a previous security-related upgrade we made.
And then we found the problem with the logs. It was actually quite simple. It always is. And it was, obviously, a human factor. Apparently someone had forgotten to switch logging from debug to live, and since we had different logs from both debug and production (live) versions, the system simply was not showing the logs that could have triggered the alarms and made us act in the first place. Hurray for robustness but thumbs down for reliance.
And there it was. All that time it was just a simple mistake that prevented us from acting in a timely fashion and looking like superheroes in a blockbuster movie, saving the day and riding towards the sunset (wait, what?).
Educational Logging Moment #2: Got Power?
And now for something completely different!
Picture another game that we’ll call Power Log Hell. This game is very popular, a big hit for company X. When the game finally got proper instrumentation and monitoring tools, there was something that started to pop out. Every single hour, during peak concurrency time, we would see a huge drop in connections, as if for some reason, a huge chunk of the player demography simply got disconnected.
No one knew what to do. There was no logical explanation. Logs told us nothing and nothing was what we had to work with. Our tests revealed no plausible explanation as logs were being properly recorded, instrumentation was correct, and the server worked like a charm — the disconnects were coming right from the client. But still something was missing from the equation. Something foul was at play.
As with all difficult situations in life, we asked for help. And help came, in the guise of our friends: logs. We started to log more information about the disconnects, in the hope that more data would shed some light.
And it did.
We started to notice a pattern. Most of those disconnects were coming from one single country: Pakistan. Why, of all reasons, Pakistan? Data was right. We double-checked everything and we even saw a similar pattern in Brazil. But what could this mean? Our server instances for Asia and Latin America were working non-stop and nothing else was to be found.
Until one day.
During an informal talk about this same issue, a couple of programmers were trying to figure out what could possibly be the case. This was during the lunch hour, where, by happy coincidence, one of the new guys was sitting right next to them. The new guy was originally from another country. Guessed already? You are right: Pakistan!
“It’s like they shut down the power every single hour!” one of the programmers said out loud in despair, as if it could bring him some closure on the whole problem.
“Yeah, we get that a lot. It’s because of the air conditioners, I think.” said the new guy, completely unaware of what the issue was about, as he was picking up his plate and moving it to the sink.
They get it a lot.
The programmers just stopped their conversation, looked right at him, and one of them said, “Come again?”
And that was the end of it. Thanks to the changes we did in the logs (and some extra help from Lady Luck), we were able to figure out the great Pakistani mystery.
Whenever I walked past the live monitoring screens, I always smiled at the saw-like charts.
Lessons Learned
One of the first things you learn when you get to that fabled entrepreneurial mindset is that there is no such thing as failure, only experiences that we can learn from. Regret will not bring the past back just like you can’t plot your way back simply from looking at the ripples caused by a moving ship. Only the present matters as everything else is an illusion.
Metaphysics aside, I’ll bet that Chris learned a lot by his investment experiences, whether they turned out to be “good” or “bad” decisions. Same thing, on another level, happens when you make software.
If I’ve learned anything throughout my career, it’s that you should expect the unexpected. You can never be 100% prepared. Not even 60%. Control is an illusion. What you can do, however, is minimize the impact of things going wrong. Nowadays I do not even consider the possibility of launching a product without having proper monitoring tools in place, whether they are raw instrumentation or detailed analytics. (I recommend you always do both because you always need to know how many players are on board at a given time whilst noticing that you are getting a lot of churn at level 4.)
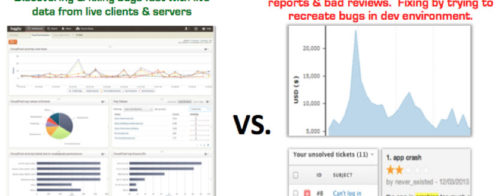
Loggly has allowed me to get some pretty interesting data on a recent project giving me insight into occurrences that I had no idea could happen and had not left any deliberate monitoring code for them.
And the best part of all this: it was so easy to implement!
I have become a fan, and I feel I have yet to discover all the possibilities it has to offer. I hope that in the short term I am able to share with you how impressive my experience has been and offer you new reasons to start using this incredible platform.
About Tiago
Tiago Loureiro is a 20+ year ITC industry professional, who has spent the last 13 developing videogames. He:
- Brought 8 Ball Pool from web to mobile while working at Miniclip as a Producer, a seamless transition that drove the app to #28 on the United States top-grossing Appstore chart
- Was featured in the Unity newsletter for developing a “Minority Report”-like software that was used in the European Parliament for educational purposes
- Has been invited to lecture on many academic and training institutions, including media schools, universities and corporate training units, in both Iberian and Nordic regions
- Works as a contract programmer as well as motivational speaker and career coach, horse trainer, and holistic healer
- Involves himself in humanitarian, green-tech and off-the-grid sustainability causes
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Tiago Loureiro