Debugging REST APIs with Loggly
REST APIs and the Cloud were made to go together. Stateless services with limitless scale means a well-designed API can deliver a service for a few hundred users, and ramp up to serve hundreds of thousands of users without any changes to code or config. But with multiple server nodes running somewhere far away (and most likely without a support team watching over them) you need centralized monitoring so you can be alerted to problems quickly and track them down easily.
A client of mine recently went live with a new product, backed by a fairly simple REST API. Our timescales were compressed, so to deliver all the functional requirements for the first release, we knew we’d have to sacrifice some non-functional requirements. We also knew the expected load profile was 2,000 requests per second, so the API had to be performant as well as fully functional.
With just three 2-week sprints before the first UAT cycle, we made the choice to sacrifice instrumentation, which is something I don’t like to do and don’t recommend. But we had a good range of unit, integration and acceptance tests so we were confident of the quality, and knew we could add instrumentation in a later Sprint when there was some more slack in the project.
There never was any more slack in the project though. With a week before the press launch, we still had no instrumentation when we found a nasty issue that we couldn’t replicate on demand, but seemed to happen more frequently with more users accessing the API. It was a strange issue – some resources returned a 404 not found for some users, even though they existed and returned 200 OK for other users.

I reviewed the code from the entry point down but there were no obvious issues, and I couldn’t reproduce the problem in dev.
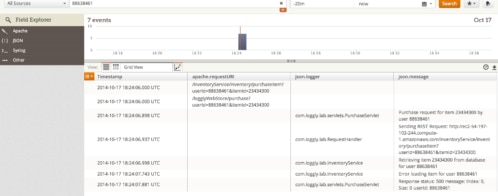
We needed some good logging to help us track down the issue in UAT from our cloud servers, so I plugged Loggly into the API. We’re using .NET and there are Loggly packages for the main logging frameworks – NLog and log4net – so in 20 minutes we had a new build deployed to six servers in UAT, which sent events to Loggly for all GET requests and responses so we could start the analysis.
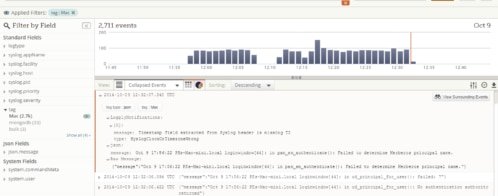
It’s straightforward to configure the log4net appender to send JSON to Loggly, and the automatic field parsing that Loggly does means you can search and filter by any field in your JSON payload. So we let the UAT guys do their work on the new release and then searched for “Response Sent” events which had a “Status Code” field value of 404. In the Loggly dashboard, you can expand the search results to include events which happened at around the same time, so we had a bunch of GET request and response events that happened around the same time as the 404. Then we filtered by the path field in the “Request Received” event to see all the events representing GETs for the same resource that returned the 404, before we actually got the 404.
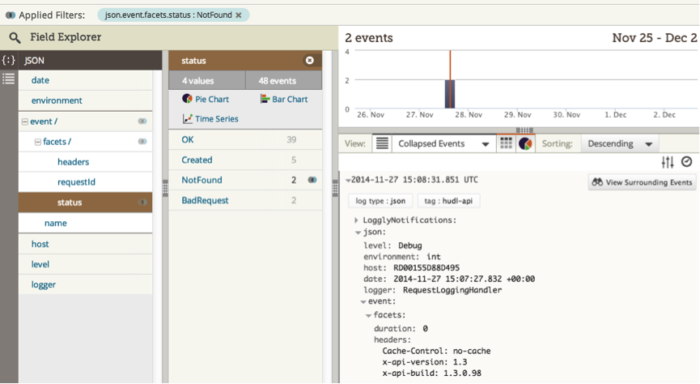
That helped me narrow down where the problem was happening, so I added some DEBUG level events in the repository layer and extended the event payload to include a correlation ID so I could track a single request all the way through just by filtering for correlated events by that field. Adding more events is simple once you have the logging framework in place, so in 10 minutes the new release was deployed, recording all those extra events.
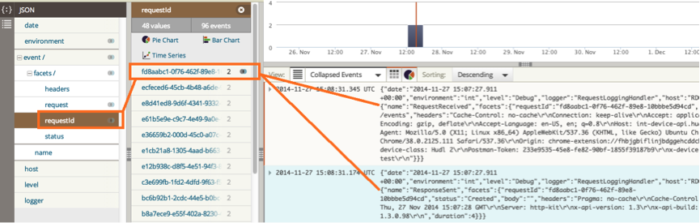
In the event stack for a request which got a 404, I could see the issue was with the cache in the repository layer. I’d suspected it may be a threading issue, so I’d added the executing thread ID to each log event and it did look like that was the problem. But when I made the code threadsafe for the next release we still had the issue and it took some more DEBUG logs, one more release, and some more Loggly analysis to find the real problem.
It was a nasty one. In one path through the code objects were being added to a memory cache without being serialized. Typically I serialize anything going to a cache, so the cache just holds strings, because that means you can easily switch between memory and other cache types; but in this case one object had been missed. The code path went on to modify the object, which meant it got modified in the shared cache, so if the next request came in while the cache was still fresh, it got the modified object and that led to the 404. The cache was only short-lived so after 30 seconds the issue would go away, which made it even harder to debug – but the logs were still there to help track it down.
This was the first time we’d used Loggly in anger, and the lesson learned was: Use Loggly all the time, for everything. The automatic parsing of JSON fields means you can easily add to your payload between releases, and the new fields are just there for searching and filtering. With a Pro subscription, you can archive off old logs to S3 cloud storage, which also makes Loggly a perfect fit if you have regulatory requirements to keep audit trails.
With any log sink you need to be mindful of how much it costs to write to the log. The cost is greater with a remote sink, but the benefits far outweigh the performance cost. Depending which stack you use and which logging framework, you can post your log events asynchronously and batch them up, so the API response doesn’t get slowed down by the logging.
In production we run at WARN level which means we very seldom write events, so there’s a negligible performance hit. In test environments which aren’t about performance, we run at INFO level, which means we can understand issues very easily. With every 500 error from the API we return a unique ID to the client and include that ID in the log event. When defects get raised the testers just add the ID to the ticket, we search for the event in Loggly, expand it to include all events with the same correlation ID, and we can see the whole stack trace for that API call, even if the error happened a week ago.
We’ve added Loggly to all our cloud-hosted products, and I’ve added it to my list of essential tools for building REST APIs.
It’s the best in its class for remote monitoring and provides an unbeatable service for the price. Without Loggly, it would have been a much harder task to track down our nasty API bug – collating and searching through log files, or writing a custom log sink for ourselves. And I’m pretty sure it would have taken 10 times as long.
Elton Stoneman is an independent consultant, Microsoft MVP and Pluralsight author specializing in systems integration. With 14 years experience designing and delivering successful solutions, his clients have been market leaders across sectors, including legal, retail and finance. Elton is an Architect focused on business value, quality and efficiency in all aspects of design and delivery. He lives near London with his wife Nikola and their son, Jackson. Follow him on Twitter: @EltonStoneman, and read his blog: geekswithblogs.net/EltonStoneman. Want more API tool recommendations from Elton? Take his new Pluralsight course: Essential Tools for Building REST APIs
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Elton Stoneman