Recreating (and preventing) last week’s AWS Availability Zone outage using Kubernetes
Infrastructure as a Service providers like Amazon Web Services (AWS) provide massive opportunities for application and operations teams to deploy services that are failure tolerant. However, teams must build their applications to take advantage of this failure tolerance before they can see the benefits of it.
Last Friday, June 1, 2018, a single availability zone (AZ) in AWS began experiencing connectivity issues. Applications, databases, and other services that happened to be on the failed AZ suffered outages for up to several hours. For the unprepared, downtime because of an upstream issue can be devastating. An analysis of multiple industries by Gartner placed the typical cost of a downtime event at $5,600 per minute. As a service provider, your customers often don’t know or care where your services are hosted, and being resilient to outages is your company’s responsibility.
In this article, we’ll describe how an AWS outage can affect your services and best practices to survive an outage without it affecting your customers. We’ll show an example of how Kubernetes can automatically recover lost capacity in minutes. We’ll also show how to use monitoring solutions so you’ll be immediately aware of the problem and can watch the recovery process in real time.
What Is an Availability Zone Outage?
AWS’s data centers are distributed through multiple regions around the world, and each region contains multiple availability zones (AZs). Availability zones are designed to make each region more resilient to failure by providing isolated sets of resources. If you host your services in multiple availability zones, an outage in one won’t affect the other–assuming things are architected correctly.
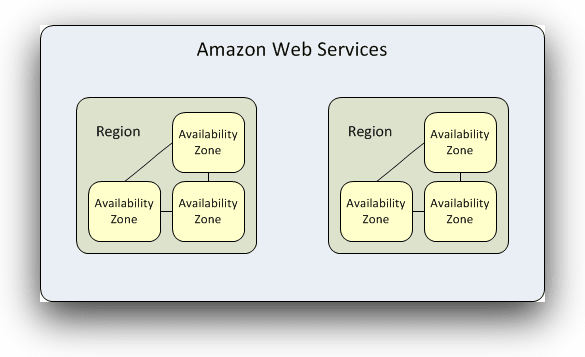
A key to building resilient applications is to deploy them in multiple availability zones, but doing so adds complexity because you need to load balance between them and account for the cost of additional servers as well as cross-AZ traffic. For some businesses, it also makes sense to run infrastructure in other regions, but that creates a much more difficult logistics problem as applications need to then manage latency and data issues that come with large geographic span.
Taking advantage of these resources will add costs to your running infrastructure, but it is much less expensive than losing business and engineering productivity due to an outage.
Kubernetes + Monitoring for Highly-Available Systems
When users are placing services and workloads, many simply pick one AZ and move on to the next step. However, applications that are built for automatic failover to another availability zone are able to recover quickly from this. Successful failovers require several factors:
- Monitoring and alerting tooling
- Workload scheduling automation
- Modern DevOps practices
Netflix is famous for having a resilient infrastructure. It has survived availability zone and S3 failures without incident. Netflix practices a technique called chaos engineering. This is like running continuous fire drills through parts of your building all day, every day, to create resilient, decoupled systems that can withstand issues that would not be discovered in manual testing. Netflix runs services like Chaos Monkey which randomly and continuously changes the availability of different parts of its infrastructure. This prevents the DevOps team from creating brittle systems out of static environments or from becoming afraid to change the environment their systems are deployed in.
One crucial best practice for highly available applications is to have an orchestration or configuration management solution that can automatically create a failover from unhealthy to healthy nodes. One popular orchestration solution is Kubernetes. We’ll show how Kubernetes and its associated components can detect node failure and move containers and routing to healthy nodes. To iterate quickly and get a full view of what is going on under the hood, we will use a 3-node Kubernetes cluster deployed on us-west-2 in zones us-west-2a, us-west-2b, and us-west-2c.
Another best practice is to have good monitoring solutions to alert you of outages so you can quickly intervene when needed. Below, we’ll show how you can use AppOptics for monitoring the infrastructure and health of our hosts. We’ll also show how to use Logglyto search the logs and investigate the root cause of the problem quickly.
Simulating an AZ Failure with Kubernetes
We will start with a simple “echo” application that echoes any requests made against it, deploy in a multi-AZ resilient fashion, and see how it handles AZ failure. All of this will happen inside our Kubernetes cluster. For reference, here is the deployment manifest we will be using:
yaml apiVersion: apps/v1 kind: Deployment metadata: name: echoheaders spec: replicas: 3 selector: matchLabels: app: echoheaders template: metadata: labels: app: echoheaders spec: containers: - name: echoheaders image: k8s.gcr.io/echoserver:1.4 ports: - containerPort: 8080 strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 0 maxSurge: 1
If we access our service via the Elastic Load Balancer our Kubernetes cluster created, we get the following:
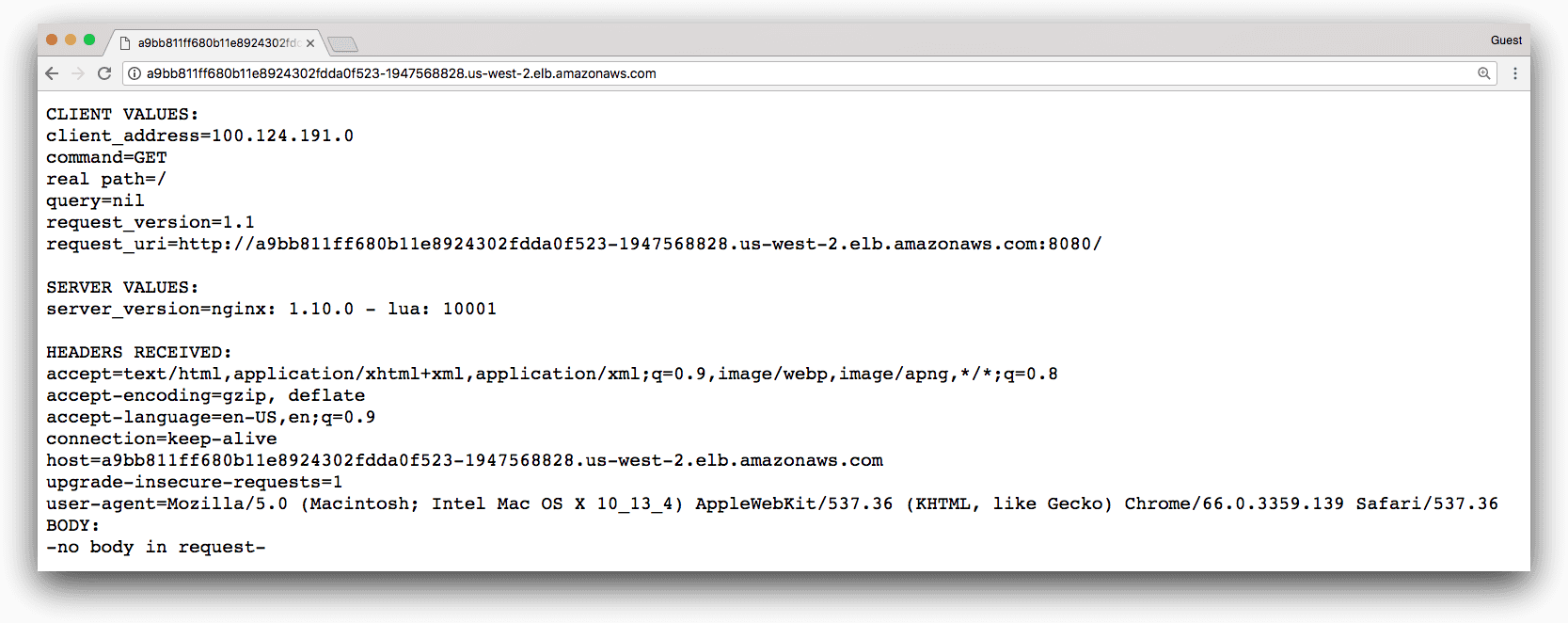
Great, looks like it’s up and running–how can we make sure it stays that way?
We have Loggly set up with the Logspout adapter, and AppOptics set up with the Kubernetes agent installed. Both of these provide monitoring and alerting, which we’ll examine shortly. They can be installed in minutes using a Kubernetes manifest or Helm chart.
Let’s start generating traffic for this cluster via a load testing tool. We then switch to the “Chart” view in our Loggly search and split by syslog.appName. In this view, we can see traffic being served to each individual pod, illustrated by the three chart colors:
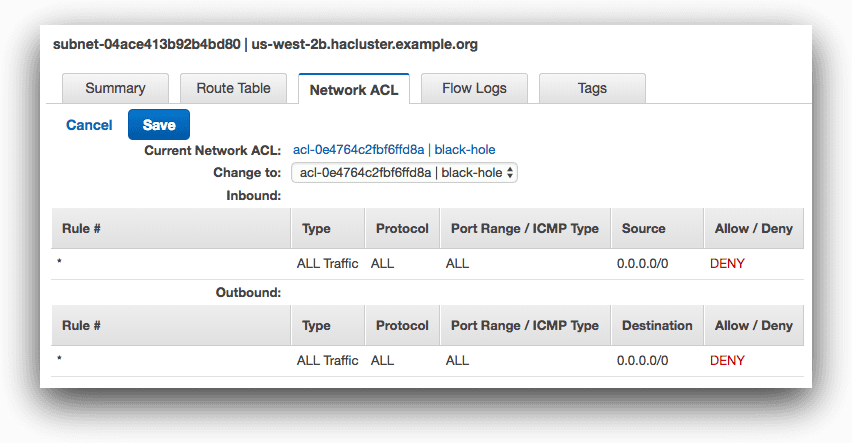
Traffic is balanced between our pods, thanks to the ELB and our kube-proxy component load balancing between hosts and pods. Now, we can simulate an AZ outage by cutting one of our subnets from the rest of the cluster. Using the subnet network ACL features of AWS, we create a black hole access control list (ACL) that blocks all traffic to and from the us-west-2b subnet.
After saving the changes and cutting off traffic, AppOptics’ ELB integration shows that the number of healthy hosts in our cluster has dropped from 3 to 1:
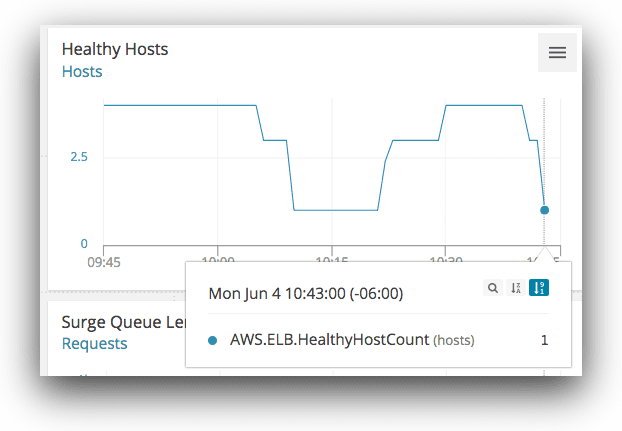
Looking into the problem more on Loggly using the split chart we generated in the last step, it’s clear what happened:
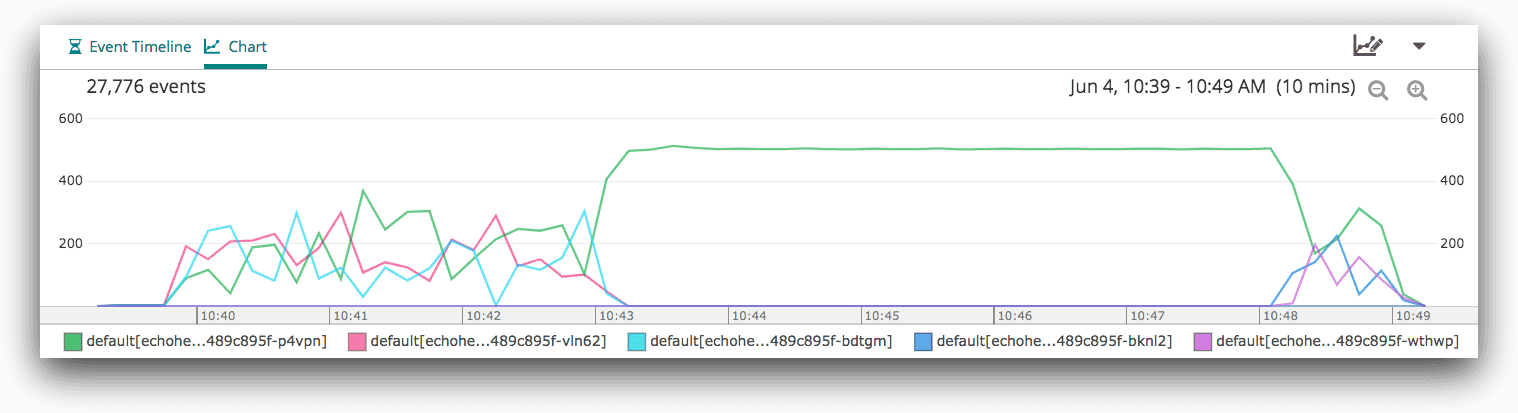
After losing our node in us-west-2b, one pod shown in green took over the remaining traffic while 2 pods went down. By default, Kubernetes won’t evict missing pods for 5 minutes (this is configurable), so this node took on the workload for the entire application. After the eviction time out, our new pods were scheduled, and traffic resumed to 3 pods. Users were able to continue accessing the application at all times during the outage and weren’t impacted by the AZ failure.
We can also observe the number of replicas of our service available using AppOptics:
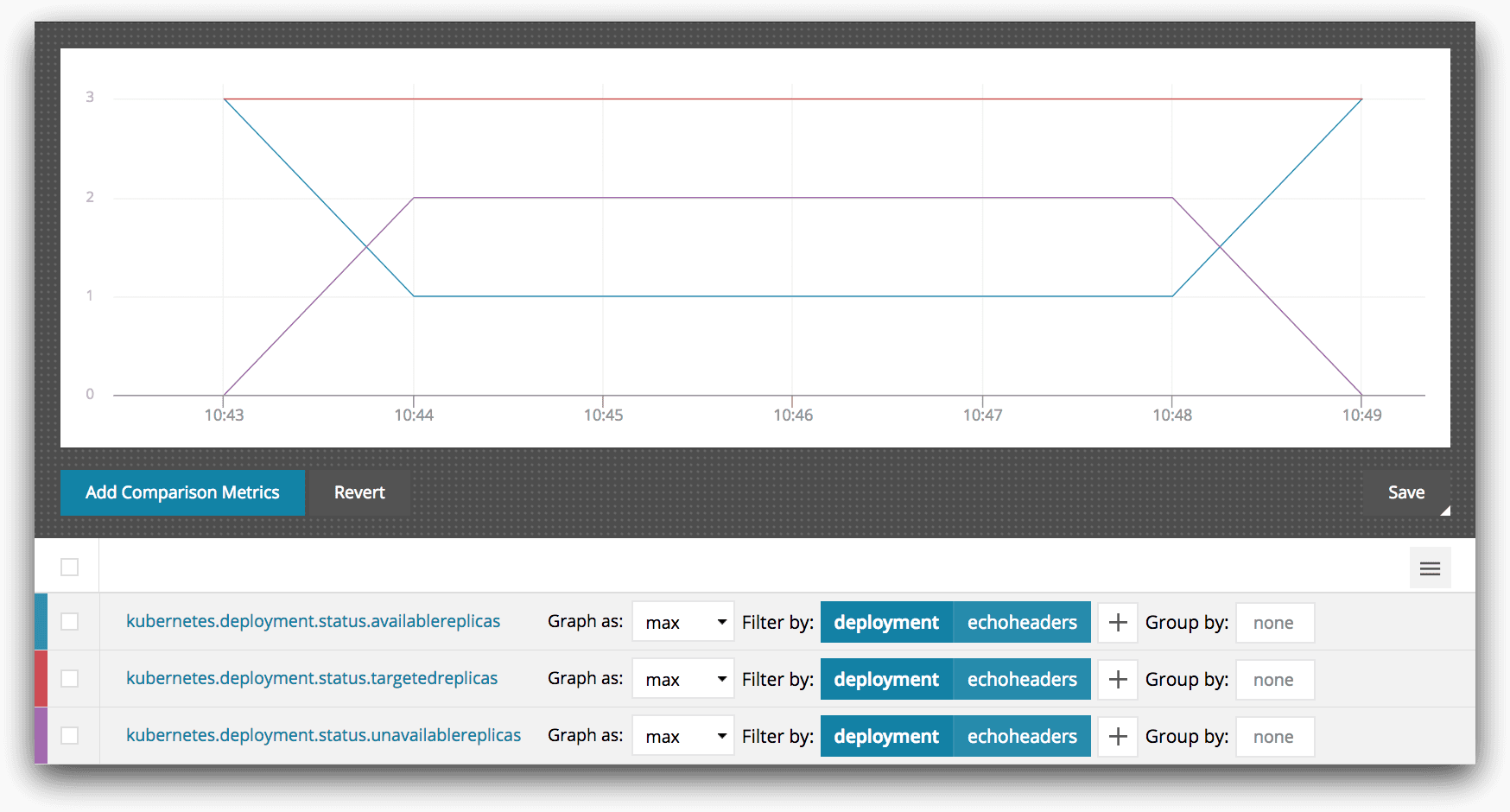
At no time does the available replica count drop below 1. From the end-users’ perspective, there was always a process available to serve their request so they don’t perceive any outage. At worst, our users experienced increased latencies while waiting for the pod evictions to take place.
Without good monitoring we’d have no way to see this information, much less act on it. Thanks to AppOptics and Loggly, we have a proactive solution for monitoring and alerting that makes us aware of the state of our infrastructure at all times. Even better, the solution required minimal effort on our part: just deploying Kubernetes manifests for the AppOptics agents and Logspout agent.
Conclusion
Creating a highly available system can help your service survive outages and deliver a consistent and reliable service to your customers. Even after an availability zone outage, your service should continue to operate as normal; ideally, it will automatically recover in a few minutes. A highly available system requires good engineering practices and the right tools. Automating failovers using container orchestration or configuration management solutions is a big win.
Equally important are monitoring solutions like AppOptics and Loggly so you’ll be immediately aware of problems from regular bugs to full available zone or region outages right away. You’ll be able to see whether your automatic failover processes are running and recovering the system successfully or whether they need manual intervention. With the right tools and best practices, you’ll survive the next AZ failure without throwing your Friday afternoon into chaos.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Gerred Dillon