Are You Wasting the Power of Your Regexes?
The Fallacy That Log Analysis = Search
When people visualize a log management solution, they often think of a bunch of logs and a search box. After all, that’s what most log management vendors focus on. They are investing in putting more and more power into the search box with their own custom search syntax and of course allowing for advanced definitions like regular expressions (aka regexes). Sounds great, right? More power in the search box means faster ways to find my answers?

Not exactly.
The Loggly Belief: Search Is Not the Best Entry Point
Search is great when you know what you are looking for. But all too often, you don’t know where to look when you first spot a problem, so you guess. And guess again. These trial-and-error queries can take up a lot of valuable time. And you’ll never find the things that can hurt you the most: the ones you didn’t know to look for. At Loggly, we believe that search is an important tool for finding answers in log data but that it is not always the best place to start.
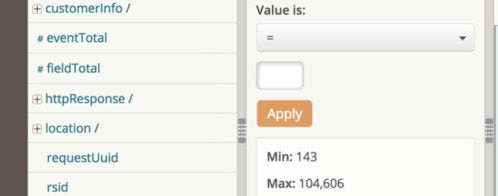
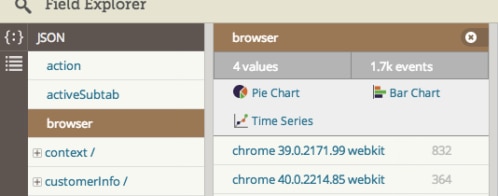
We built Loggly Dynamic Field ExplorerTM as a way to turn the search paradigm around. By generating navigable summaries of your data, you have a bird’s-eye view that exposes both the most common events and the anomalies, as well as providing a quick and precise way to hone in on specific logs and filter out the “noise.” Wouldn’t it be great to have this kind of powerful analysis for both structured and unstructured logs?
But I Digress… Back to Regular Expressions
I see a lot of customers working to convert their logs to JSON, but we know that unstructured logs won’t go away any time soon. Your logs may be coming from legacy systems, where you don’t have control over their format. You may not have the development resources right now to optimize your logs. As such, regexes will continue to be a key ingredient in using all of your log data effectively—as long as you use their power in the right way.
Single-Use Search Just Wastes Power
The conventional approach is to use regexes as part of the search workflow (whether it’s with grep or a log management tool). If you’ve done followed this path, you probably put a fair amount of effort into constructing the “perfect” regex for your needs. But this workflow does not provide the ideal path to leveraging this work in future analysis. Can you share your work with colleagues who may need similar analysis? Sure, you can probably save that search query so it’s always a few clicks away. However, using regexes during live troubleshooting not only limits the number of people who benefit but also creates a huge burden for a couple of reasons:
- If you are using regex queries to both match events and extract fields to do some calculation or aggregation, you know this can be painfully slow over large data sets. Since troubleshooting is rarely a one-search effort, this means you have to wait (sometime minutes or hours) for the regex rule to parse fields live on every new set of search results.
- All the fields extracted and calculations from your masterpiece during search are not saved. So when your colleague wants to see the same results, he or she also has to wait for the regex to be processed once again. Great, now you passed the burden on to your whole team!
If your colleagues want to take a slightly different cut of the data, they can update your saved search or create their own. But once again, none of the outputs of their keen insight is saved for others to leverage, creating an endless cycle of lost knowledge.
Create Derived Fields to Best Leverage Regex Power
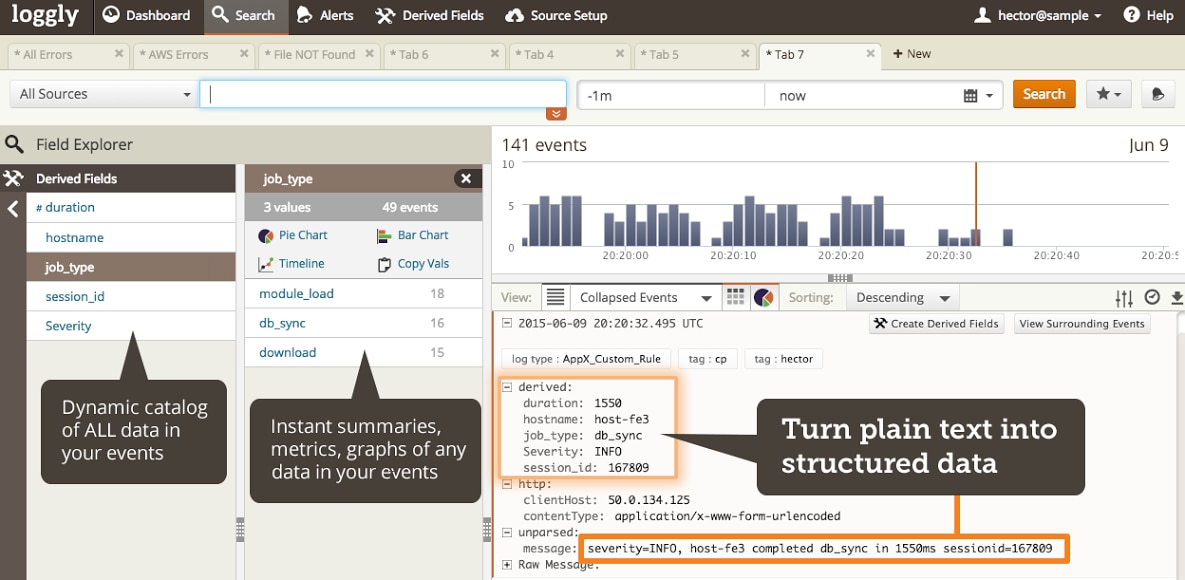
Loggly Derived Fields give you a way to define custom parsing rules that generate derived fields as metadata as your logs are received by Loggly. The derived fields provide intelligence and structure that is then used by Loggly Dynamic Field ExplorerTM to automatically catalog and summarize logs for one-click navigation and analysis.
We designed Loggly Derived Fields to eliminate the shortcomings of using regexes during search. You’re still able to leverage regexes to create powerful matching and field extraction rules, but we take their practical burden off your hands by automatically applying them to your data during ingestion. This means by the time you log in, your data is fully structured and ready for advanced analysis… on every single search, aggregation, and graph you do. And, you can now use Field Explorer to navigate through automatically derived summaries of your data. Now, you can spot not only what you knew to look for but also the surprises.
Four Benefits of Derived Fields (Using Regex the Right Way)
- Have any log (even legacy logs) automatically parsed at ingestion time so that your data is already structured the way you need it, any time you visit Loggly.
- Get automatically generated summaries of what’s in all your logs BEFORE you type a single search command.
- Add your knowledge of what a log event is really saying as metadata into the log so others on your team can more easily interpret and navigate the data.
- Have a way to extract different, customized views of the same log data without relying on your logs’ structure or changing the existing data.
See How It Works
View our dynamic field explorer webinar where I demonstrate derived fields and show how they extend the value of Field Explorer.
Of course, you can always experience derived fields with your own log data by signing up for a Loggly free trial.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Hector Angulo