Building a SaaS Service for an Unknown Scale: Part 2
In my last post, I made a case for how scalability and reliability have a new meaning in the SaaS world and shared two important building blocks for SaaS success:
- Creating an architecture that’s not only multitenant but also made up of stateless components that can scale easily, with data processing lanes and service governors to serve as safety nets in the event of application problems or unexpected (and often undesired) customer behavior
- Building a metrics API and an action API for every application component
In this post, I’ll delve into four more SaaS architecture best practices, which build on the core principles we discussed in the first part of this series.
Best Practice #3: Build for Unpredictable Loads and Behavior
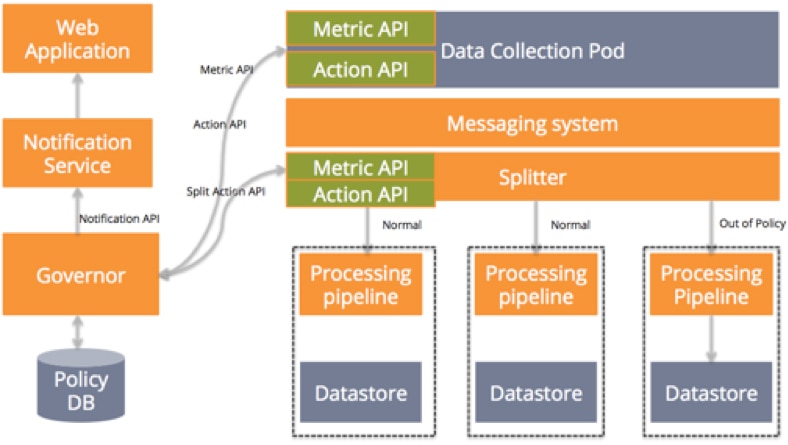
It’s inevitable that customers will send data or use service in an unpredictable or not-so-well-defined manner. With Loggly, we have seen customers unintentionally send huge amounts of data to our service because of an issue of one kind or another in their systems. (We call them “noisy neighbors,” and they exist for every kind of SaaS application.) The best SaaS applications are designed to handle this kind of unpredictable behavior, and service governors are the key. Governors protect your other customers from the noisy ones by quickly identifying noisy neighbors and processing their requests or data through separate paths.
Your service governor is the component that watches your whole service and takes actions based on policies defined for it. It is one of the major users of your metrics and action APIs. It:
- Consumes stats from the metrics API
- Applies governance policies based on those metrics
- Uses the action APIs to take the appropriate actions dictated by those policies
Let’s say that some customer suddenly starts sending an enormous bps load to your service. The governor would use metrics from the data collection pod to detect the increased activity. It would look at your defined policy and then invoke the action API on the data collection pod, the action API on the splitter, or both. If there is a need to notify the customer, it would invoke the notification service to send an appropriate notification. Below is the architecture diagram of our sample application with service governors, notification service in place.
Best Practice #4: Build for Data Corruption
The next factor to consider is how your SaaS service will handle data corruption. Data corruption will happen, whether through human fault, machine fault, or software bugs. Building your SaaS service in such a way that it can recover from these faults is a key aspect of its reliability.
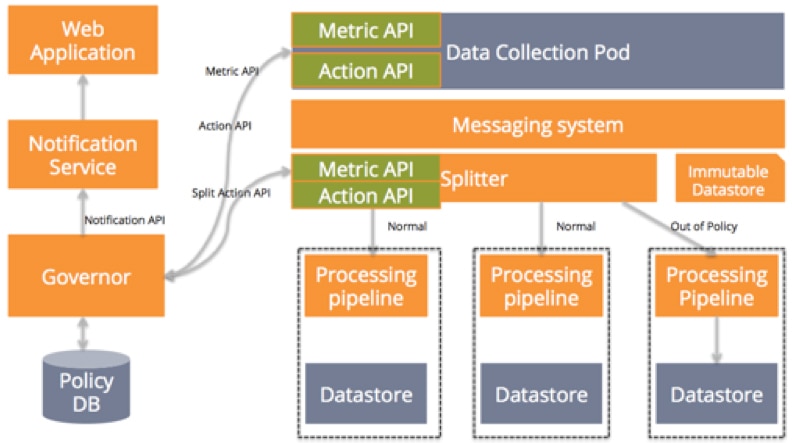
Building for data corruption requires a separate data store that maintains all customer data unmodified. The moment that data enters the service, it goes to this immutable store where it can’t ever be modified. Most storage systems provide basic CRUD (create, read, update, delete) functionality. However, to have truly immutable data we should use only the create and read functionality provided by storage systems. In our example, the immutable store can be added off the messaging system because data collection pod collects but doesn’t modify customer data. Now, if your data store gets corrupted for any reason whatsoever, you can recover the data from your immutable data store.
You should make sure you pick an immutable store that can be plugged to your processing pipeline easily without any manual work. You should also be able to send data from this store to your processing pipeline based on time ranges, customer sets, etc. Finally, I recommend that you have a separate lane for rebuilds instead of using the normal lane so the real-time data coming into your application doesn’t experience a performance penalty because of rebuilds.
Best Practice #5: Ability to Increase Capacity on Demand
As your business grows, customer data grows. You need the ability to increase the capacity of servers or components in your service quickly and painlessly. Adding servers manually is painful and error prone. Worse yet, the process can cause outages or result in your service running in a degraded mode.
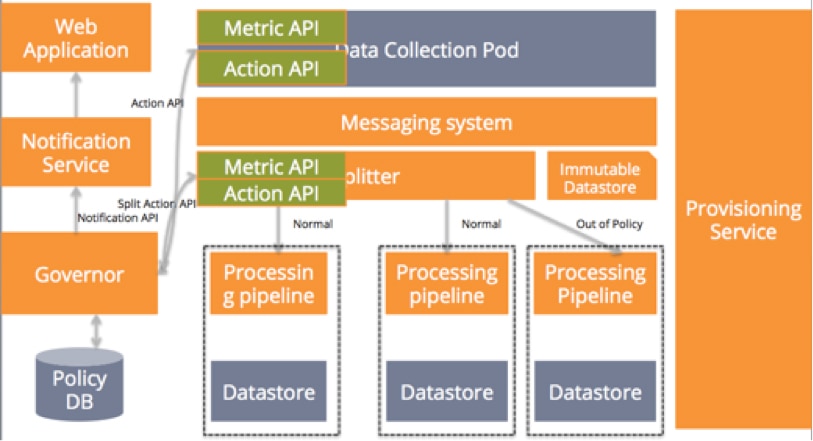
So how can your application recognize that it needs more capacity and add this capacity on demand? By adding a provisioning service to your stack. Here’s what that service would do (assuming that your service is running on AWS):
- Make periodic calls to your metrics API to compare the current load with your current capacity. Doing so will help in detecting if you need to expand or shrink capacity. Going back to our sample application, the metrics API for our data collection pod can be used to detect when the incoming data to the collection pod reaches the maximum threshold that can be handled by existing capacity.
- Use the AWS API to spin servers as demand grows.
- Get the package to provision from your package repository (I did not show the repository in the diagram below for simplicity.)
- It gets the inventory of our systems and their role from inventory list.
You can build your provisioning service with your choice of framework like Ansible, Puppet, Chef, etc. Or you can use a combination of AWS services like CodeDeploy, CloudFormation, OpsWorks, or the AWS boto API. Like your governor, your provisioning service should get metrics from all the components so it is capable of spinning any component in your stack. (This is another reason it is good to have all components stateless.) And with your provisioning service in place, your service doesn’t require any manual intervention if it needs more capacity.
Best Practice #6: Ability to Roll Out Fixes, Patches, and Releases with One Click
More and more SaaS companies have seen the need for continuous integration (CI) and continuous delivery (CD), which have been a natural evolution of the agile development methodology. Agile simply can’t be successful without CI and CD. The caveat: It requires a lot of infrastructure and resource to build CI and CD into production environments. If you have the ability to put such infrastructure in place, then I recommend having CI and CD for production. If not, you should have CI and CD for your development and test environments and one-click deploy for production. You can actually think of your provisioning services in two parts:
- Spinning new machines or VMs
- Deploying the right set of packages on each machine based on its role. And in the same way, deploying new releases
Summary
The very nature of log management made it an imperative for Loggly to build our solution to handle an unknown and unpredictable scale. But virtually every SaaS business faces a similar set of challenges:
- Growth curves that rarely track to your company’s projections
- Unpredictable loads, in which one “noisy neighbor” customer can affect everyone
- Data corruption, whether through human factors, machine factors, or software bugs
- The need for much more frequent releases than you might expect
Loggly’s segmented pipeline has made it simpler for us to:
- Manage growth in our business
- Ensure that problems in one cluster won’t have an impact on other customers
- Streamline the process of offering upgrades
- Offer specific features within each Loggly subscription plan
We’re positioned to take on these potential headaches for tens of thousands of net-centric companies that need insights from their log data so they can focus on what really matters to their end customers. So if you haven’t done so already, start a Loggly free trial so you can stop thinking about the scalability issues around log management forever.
And stay tuned to the Loggly blog because I’ll be digging into more SaaS scalability best practices over the next several months.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Manoj Chaudhary