Does error monitoring spell the end of logs?
“You don’t need to log anymore!” At least, that’s what some are claiming will happen once you implement an error monitoring solution. At first glance, the benefits of error monitoring tools are clear: They can monitor applications in real time, provide useful metrics on resource usage, and immediately report any unusual or unexpected events. But this is by no means an alternative or replacement to logging, and in this post we’ll explain why.
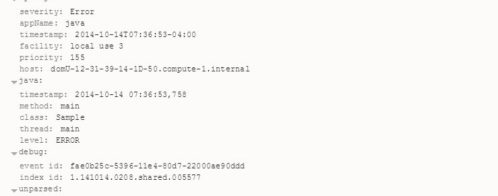
First, let’s define what error monitoring is. Error monitoring tools are used to detect critical events in running applications almost in real time. Most error monitoring tools take the form of independent processes or agents running separate from the code that they’re monitoring. For example, an error monitoring tool for a Java application will actually attach to and extract data from the JVM in which the application is running. This gives the tool access to detailed information such as call stacks, memory allocation, and even garbage collector activity.
In comparison, logging tools are embedded in the application itself and must be called before they can start recording data. At some point during the application’s runtime, a logging driver is explicitly referenced and a new event is generated based on parameters set in advance by a developer. That same Java application might use a framework such as Log4j to write a log event whenever an exception occurs.
Both of these approaches have the same goal, but they go about it in different ways. The question is: can one completely replace the other?
Why can’t I replace logging with error monitoring?
The fact is, logs are extremely good at what they do. They offer several benefits that can’t be provided by other reporting solutions, including error monitoring tools.
Traceability
A key part of problem resolution is tracing the error back to its source, often by following calls on a stack trace. Many logging frameworks can help with tracing execution flow by tagging log events with class names, method names, or custom identifiers. For example, Log4j’s Thread Context lets you “stamp” a unique data point (e.g., a user ID or other variable) onto any logs generated until the data point is removed. For example, to trace the path of a specific user, simply search for log events tagged with his or her user ID. With granular logs, you can even see each function call made during the user’s session. Many error monitoring tools provide some degree of traceability, but may be limited in how much detail they store or how far back they archive events.
Traceability is also important in environments where your application is distributed. What happens if you have a microservices-based architecture where your frontend, backend, and middleware are three separate systems? If we’re tracing a user’s session, logs can show us which services interacted with the session even if the service no longer exists.
Lower overhead
Since logs are only generated when the application code calls for it, there’s no need to have a separate service constantly running in the background. Although logging can incur a performance hit, logging frameworks have gotten faster over time. Even older frameworks can perform thousands of synchronous calls without hogging resources. Error monitoring means having to run a separate service alongside your application, which can become a problem if you experience spikes in CPU or memory use. Some error monitoring tools even require logs in order to function, increasing overhead even further.
Reusability
A single log event can take many different paths. It might be displayed to a console, shipped off to a cloud service like Loggly, or written to a file. Log events can be easily redirected, parsed, stored, indexed, copied, and archived. An error monitoring tool may be able collect log data, but your ability to reuse, export, or analyze that data is solely determined by the tool’s creator.
Example: Monitoring a website on AWS
Both logging and error monitoring can help you troubleshoot and harden your applications, but that’s not to say you should only use one or the other. Using both approaches simultaneously can greatly improve your ability to detect and resolve problems before they grow out of control.
As an example, imagine a website running on AWS. Our website uses a simple LAMP stack running on Elastic Beanstalk, or more specifically, ECS (Amazon EC2 Container Service). As part of our deployment strategy, we want to collect metrics on everything from CPU and memory usage to failed database calls. Elastic Beanstalk already provides basic health reporting such as uptime, average load, and traffic, but this only gives us a surface-level view. If we do notice an anomaly (a sustained spike in CPU usage, for example), we have little to no information to go by other than its effect on resource use. And while Elastic Beanstalk can retrieve logs from containers, they can only be retrieved on demand and are deleted after 15 minutes, making it difficult, if not impossible, to analyze them effectively.
As a solution, we can forward events from ECS to Amazon CloudWatch Logs, which ingests log data and scans it for specific words or patterns. If a certain pattern or threshold is detected, Amazon CloudWatch Logs can send out an alert with specific details including the original log data. You can either send logs directly from Docker by using with the awslogs driver, or install an agent on your ECS instance(s) that will collect and aggregate the log data before sending it to Amazon CloudWatch Logs. In either case, you don’t need to make any changes to your application code or your containers.
One of logging’s strengths – especially with Docker – is that you can easily choose where to send your log data. The benefit of using Amazon CloudWatch Logs is its basic health monitoring tools and close integration with other AWS services.
Logging and error monitoring are both here to stay
We’ve seen that logging and error monitoring are ultimately two different approaches to the same problem. Error monitoring provides immediate insight into running applications, while logging provides traceability and accountability. If you’re still not convinced, remember you can always configure Loggly to keep an eye on your logs and alert you if anything goes wrong.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Andre Newman Andre is a technical writer and software developer specializing in enterprise application development. He has over a decade of experience developing software in Java, C++, C#, VB.NET, and Python. He has additional experience designing, developing, and deploying secure web applications in a LAMP environment. As a technical writer, Andre has created internal documentation, user guides, training material, and informative essays for small to mid-size companies. His work has been featured in WebOps Weekly, corporate blogs, and on popular social media outlets. When Andre's not busy writing, he's either reading up on new developments in technology or out on a bike ride.