Scaling Elasticsearch for Multi-Tenant, Multi-Cluster
When you start building infrastructure on Elasticsearch (ES), the first architecture usually assumes you can run a single ES cluster. This is the easiest way to get started: Just spawn a cluster and go.
A typical search-based application looks like this:
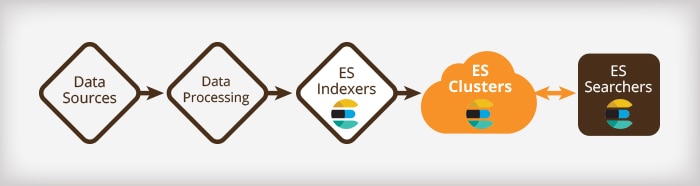
Any modern architecture will be designed for scalability and resiliency, so each stage should be able to scale to the level necessary to sustain the load it receives, while also being robust to temporary failures. ES, of course, delivers on this requirement very well (as you will see below), but a single cluster can become a bottleneck.
Big Data Increases Can Create Big Issues for a Single Elasticsearch Cluster
As your system grows, you’ll see drastic increases in both data loads and data storage volumes. When this happens, significant issues can emerge with a single-cluster ES architecture. These issues include:
- SPOF: If something goes wrong with the cluster, every single customer is affected. This is the very definition of a single point of failure.
- Ballooning Cluster State: As we have noted before, cluster state is one of the most important concepts in ES. As your data grows, your cluster state grows with it. And since cluster state gets processed with the highest priority compared to search or indexing, a ballooning cluster state can cause suboptimal performance for the functional parts of your application.
- Risky ES Upgrades: In a single-cluster environment, upgrades become more risky. You must bring down the whole cluster, and it may take a lot of time to come back up completely. In the meantime, your service is running in degraded mode.
- Long Restarts: If the cluster requires a complete restart due to maintenance or some other issue, it can take hours to come up.
Boiling this down: The bigger your cluster, the harder it falls.
A Multi-Cluster Elasticsearch Architecture Provides a Better Fit for Growing Applications
Loggly has been running an architecture with multiple ES clusters since early 2015. This approach is now emerging as an ES best practice for very large systems (hundreds of terabytes of index and up). Here’s a simplified view of what the architecture looks like:
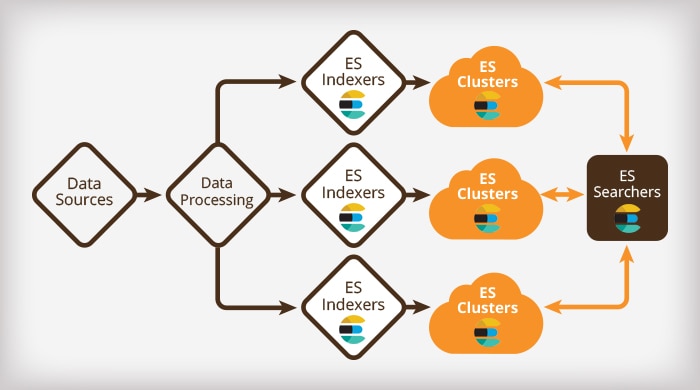
As you can see, splitting the data coming out of our main data processing pipeline lets us run independent ES Indexers for each cluster.
The Advantages of Multi-Cluster Elasticsearch
A multi-cluster architecture addresses many of the issues I described above. It gives you:
- Better Reliability: Issues in a single cluster will only affect a small proportion of your customers.
- Better Application Performance: In a multi-cluster environment, you can more effectively allocate resources for indexing, searching, and cluster state, because each cluster is smaller.
- Easier Upgrades: Not only are you upgrading smaller clusters, but you can also roll out the upgrade cluster by cluster, reducing the risk of a “Grand Slam” failure. In the worst case, it is easier to completely replace the cluster, because no cluster is so big that this becomes prohibitively expensive.
- Higher Overall Uptime: Even if you do have downtime, it is very unlikely to take out every cluster.
In the same way that sharding provides a way for ES to scale indices to take advantage of multiple machines, running multiple clusters provides a way to scale total data volume in a multi-tenant system.
Multi-Cluster ES Drives New Operational Needs
Moving to multi-cluster is not like flipping a switch. You need to put several things in place to effectively support multi-cluster ES in production:
- Automation, Automation, and More Automation: No matter how good you are, automation is the best way to deal with operational issues. Provisioning, running, and modifying your system by hand is error-prone and time-consuming. We have automated all of the routine tasks required to operate our systems, primarily using Ansible. (BTW, we track our usage using Loggly.) The following steps assume that there is some level of automation support.
- Elastic Matters: Even with the best planning in the world, you may find that one or more of your clusters are the wrong size. We know our clusters will grow and shrink over time, so we have tools that make it easy for us to detect this and take the appropriate action. (Hint: One of those tools is Loggly!)
- Pipeline Flexibility: When a new cluster is added to the system, you need to ensure it gets the right data. We designed our data pipeline to allow us to easily split data at any stage, with simple configuration changes. We deliberately decouple this from our Cluster Provisioning automation to add flexibility. We can bring multiple clusters online simultaneously, for example.
- Search Flexibility: When a customer searches its data, you have to ensure you hit the right cluster. We do this using a small piece of custom code that essentially reroutes requests to one of our many internal search clients. This lets us easily scale our search client capacity to match our demand, guarantees consistency by sharing configs with the data pipeline, and provides a little more control than any off-the-shell balancers.
- Avoid the Bleeding Edge: When you’re running many clusters, you can’t afford to run them on the bleeding edge, because they will need care and attention. We choose not to run our clusters red-hot simply because we have better things to do with our time than continuously nurse overloaded clusters back to health.
None of these are particularly complex issues, but we have seen each of them evolve over time as we gain more experience and deal with more data and more clusters. That evolution is captured in our automation tools. We work hard to make sure bringing up a new cluster and plugging it into the rest of the system is as simple and reliable as possible. After all, one of the key goals of automation is to reduce your fear of change.
How to Balance the Price of Growth
Once you have a multi-cluster architecture and supporting Ops infrastructure in place, the biggest question becomes an optimization one: At what point do I start another cluster?
At Loggly, we are continuously growing. Our incoming data is growing, searches on our cluster are growing, and the number of fields in customer data is growing. We found five parameters that we can use to track the capacity of a cluster and know when it’s time to expand. In order of importance, these are:
- Search Performance
- Disk to RAM Ratio
- Number of Indices and Shards
- Cluster State Size
- Indexing Speed (documents per second)
We track all of these values, and when we get close to the limits we’ve set ourselves, we know we need to spin up a new cluster. Our limits are all slightly conservative, because we have to account for continued growth within any of our clusters.
It shouldn’t be a surprise that search performance is the most important thing on this list because it’s the most visible metric to our customers. The disk to RAM ratio is closely aligned to search performance but is a lot easier to measure.
The number of indices and shards and the cluster state size are also closely correlated. Based on previous experience where we (unwisely) let them grow too large, we try to keep both of these within reasonable limits.
It might seem like we’re underplaying indexing speed by putting it last on this list, but the simple truth is that if all of the other factors are within our normal operating parameters, then we have plenty of horsepower to spare in the cluster for indexing. We rarely need to use our full indexing throughput, thanks to the fact that our indexing pipeline has evolved into an extremely robust piece of software.
Taking Care of Your Customers Across Multiple Clusters
In our system, a customer is assigned to a cluster at signup time, then stays on that cluster unless it becomes very, very large. Most customers will grow over time. They’ll send more data and start doing more with the product. Because we add new clusters well before the newest cluster is at capacity, we have a decent amount of built-in, worry-free headroom.
If we need to, we can (and do) expand or contract existing clusters. We have clusters of different sizes, each scaled to handle its particular load. This means that we can’t treat our clusters as identical, so our automation tools need to be a little more flexible than they would otherwise be. All clusters start out with an identical configuration, but as time goes by they evolve to deal with the changes that the customers assigned to them make. Expanding and contracting clusters is very straightforward, because ES really is … well… elastic.
To give you an idea of how much variability we’re talking about, we have clusters ranging in size from 12 to 36 data nodes, from 10 to 50TB of index, from 200 to 2,000 indices, and from 2,000 to 5,000 shards. All of these clusters perform at about the same level.
The only time we ever move a customer is when we know that they are going to grow large enough that they could cause capacity issues in their existing cluster, resulting in degraded performance for both them and the other customers in that cluster. Once we’ve decided that we do need to move a customer, we have two mechanisms we can use:
- We index their data in parallel in a new cluster, wait until their entire retention period is “covered” in the new cluster, then flip a switch so they use the new cluster for search. At this point, we also turn off indexing into the original cluster.
- We index in parallel, as above, but also move their existing data to the new cluster. This shortens the wait but is a much more hands-on process.
In reality, the first approach has been sufficient for every case we’ve had to deal with so far, and the second approach is a fallback strategy that has been tested, but never used. The reason that the first works so well is that we typically have a fair amount of notice that a customer is going to grow large enough to require moving. When we do need to move a customer, the cluster they get moved to must have plenty of capacity, so the only additional load on the system is that their data is double-handled in our indexing pipeline for a period of time.
We have looked at using Tribe Nodes as a solution to this problem. Using them, we would simply switch which cluster data was sent to atomically, and then use a Tribe Node for our searches. In testing, this works well, but there is no pressing need to deploy it, so we haven’t.
Conclusion
If you’re planning on building a large multi-tenant ES system, you’ve probably already thought about splitting different customers into different clusters. You’re probably already aware that choosing the number of shards per index carefully will maximize ES performance on your desired hardware. You’ve probably already thought about whether to use custom routing to improve your cluster performance.
Running multiple clusters just takes all of this up another level!
ES makes it easy to add a new index to a cluster, experiment with the number of shards in an index, and experiment with _routing. From a theoretical point of view, you should be able to apply your understanding of indices and shards to roughly map out how a multi-cluster system might look, specifically:
- How many clusters do you need (how many indices?)
- What is the biggest and smallest cluster you need (how many shards?)
- What data goes to which cluster? (_routing)
To build a multi-cluster system, you need to make it as easy as possible to add a new cluster, modify that cluster, and plug the cluster into your data pipeline. Automation is the key to making all of this reliable and painless.

The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Jon Gifford


{kind=link}