How to: Search Your Logs in the Real World of Log Management
Search seems like a pretty simple thing; many 5-year olds and even some 2-year olds can do it these days. In the world of log management, Loggly gives you plenty of powerful tools to search for events and filter down to the relevant results. But how do you go about turning your searches into real-world problem solving?
There are thousands of answers to this single question. No one could ever give you a log management manual that would cover them all, but here are some simple ways to think about how you can use search to make your life easier…
Direct Searching
Sometimes you know that your problem relates to a specific machine or a specific process or behavior within a single application. When you’re really lucky, your problem may even boil down to a few specific messages. In these cases, direct searching can yield really good results, really quickly.
Sometimes you need to narrow down or drill down to find what you are after. The idea is that you start with a relatively broad search (e.g. search for ERROR) then iteratively refine the query to narrow down the scope. Here’s an example:

Filters are the way to refine your queries. With every search you do, Loggly takes your initial search results and automatically categorizes them based on any of the structured fields that are in your data. They make it really easy to drill down into your data.
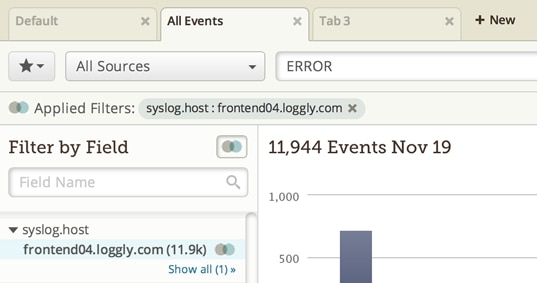
Continuing the example, you might next add a filter for a specific host such as frontend04.loggly.com in the image above. Then a specific tag. Then a specific term (NullPointerException, say). Each step along the way, you’re deliberately searching within the set of results you had for the previous search. Think of it like chaining together a sequence of grep commands. If your intuitions about what to search for are right, then by the end of the process, you should have found the signal that is telling you what broke and why, amid the noise of potentially millions of other events.
Searching by Elimination
Just as often, though, you don’t know where a problem originates, or it may be bouncing around from host to host. In this case, it’s best to do the opposite of direct searching: rather than searching for things that you know are in the search results, throw away things that you know are not relevant, using the NOT operator. Think of it as a sequence of grep -v’s.
The nice thing about searching by elimination is that you often stumble across problems you didn’t even know you had. This shouldn’t be a surprise, since the entire process is based around the idea that you’re eliminating things you know (or at least believe) are irrelevant. As Sherlock Holmes famously said, “When you have eliminated the impossible, whatever remains, however improbable, must be the truth?”
Search Tools
Fortunately, Loggly includes a bunch of capabilities that make both direct searching and searching by elimination much less painful.
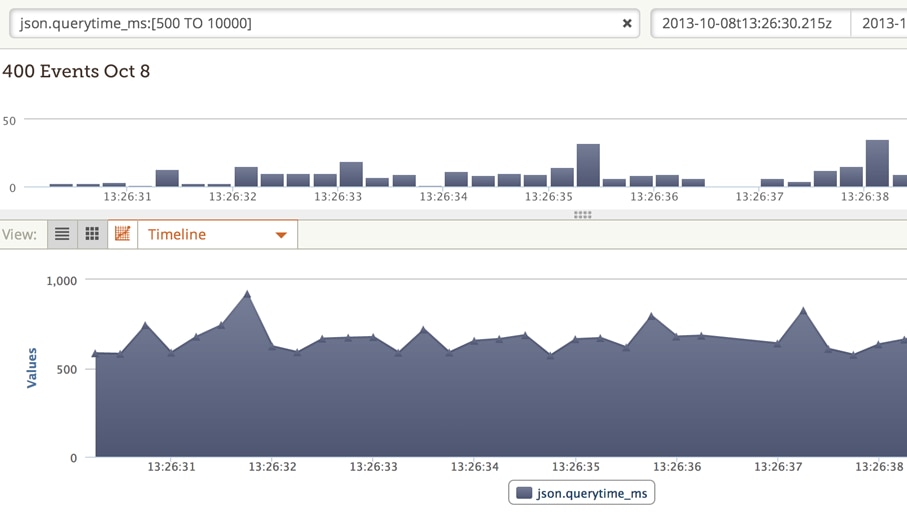
Range queries are a great way to find events that exceed certain parameters, for example database responses that took longer than 500 ms. You can see in the time series chart below that it selected responses over the threshold.
Filters also help you search by elimination. Once you do a search, filters will give you an idea of what’s included in your dataset, and what’s not. For example:
-
- If you look at a facet for host and see only one host, you know where your problem is – it may be that you’re running an old version of your code on that host, you may have misconfigured that host (or just configured it differently than its peers), or it may have a hardware problem. Alternatively, if everything looks normal on that host, you may just have a hot-spot in your architecture, and more load is being dumped onto that host because of the way you partition your traffic or data.
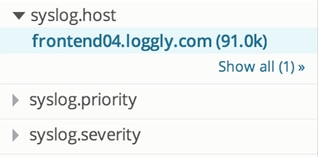
- If, on the other hand, you see 20 hosts, you can see immediately that your problem is more widespread – maybe its a bug in your application, maybe its a problem in an underlying shared resource that doesn’t show up in that resource, but only in the applications which use it. Whatever the case, the fact that you can see the problem spread across multiple machines means that when you fix the problem, all of the hosts that were “broken” should be fixed simultaneously. That’s always a good thing 🙂
Regular expressions give you a way to match patterns in your logs. For example, if you have machines named frontend01 through frontend99, you can search for /frontend[0-2][0-9]/ to narrow the scope of your search to the first 30 nodes in that set. Regex’s are incredibly powerful, but they’re also a little slower to run than normal searches.

And finally, Loggly has advanced Boolean so that you don’t have to look at one single thing at a time. Because we expose the full Lucene query language, you have a huge amount of flexibility available in how you construct your queries. Using a combination of () and AND, OR, and NOT, you can construct arbitrarily complex queries that will show you log lines from multiple applications on multiple hosts. For example:
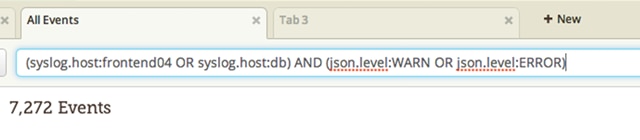
This will find any WARN or ERROR log lines from your apps running on either you frontend04 or db hosts.
Solving operational problems is not child’s play. But if you take advantage of all of Loggly’s advanced search capabilities, you’ll be able to do it faster and more productively. But don’t take my word for it, take Loggly out for a free test-drive and see for yourself.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Jon Gifford


