Six Critical SaaS Engineering Mistakes to Avoid
Before I joined Loggly as CTO and VP of Engineering, I spent years building no less than seven different cloud-based products. This experience taught me a really important lesson.
“Failing to prepare for failure is costly…
but failing to prepare for success can be even worse.”
From my perspective, I’ve identified six critical SaaS engineering mistakes separated the companies that rose fast from those who stumbled.
Mistake #1: “Adoption for our offering will take time, so we can get some experience before we think about how to scale.”
Look at how steep the technology adoption curve has become. You don’t know for sure what your own service’s curve will look like, you need to treat scalability as a P1 feature from the start. Once you have gone live, the damage inflicted on your company by a non-scalable service is just too severe to bear.
You need to be prepared with:
- Realistic adoption goals and scenarios, translated into performance, stress, and capacity testing that maps to those goals
- The ability to scale various components of the service horizontally with elasticity
No SaaS business can afford to have scalability as a bottleneck for service adoption and success.

Mistake #2: “Our customers will follow predictable behavior patterns.”
Sorry, they won’t. Be ready for something unexpected that will threaten to break your service; and have processes for managing out-of-policy activities.
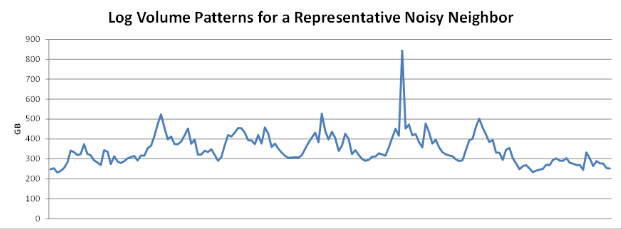
The Loggly service must deal with “noisy neighbors” who inadvertently log in debug mode or have a huge burst of log events during a production issue or fire. Below is a graph showing one such customer; note that the spike is more than twice the daily norm. We have had to design our service so that these situations don’t affect the rest of the 5,000+ net-centric companies that we serve, and other SaaS applications need to be able to handle similar scenarios from the start. I will dig deeper into the noisy neighbor problem in a subsequent post.
Mistake #3: “Governance is Marketing’s problem.”
Related to the point above, engineering a SaaS service needs to encompass not just running the service but governing it. You need a governor that sits on top of your platform and “watches” everything that’s going on in your app, across tenants. The governor needs to be able to figure out if a particular customer’s behavior is out-of-policy and to segregate the misbehavior in a way that eliminates the impact on other customers. Then, it needs to inform the right set of people to take action. Your marketing, finance, and legal teams are key players in defining and applying usage policies, but implementation needs to be embedded into the product itself. I’ll dig into this deeper in a subsequent post.
Mistake #4: “We don’t need operations automation.”
Operations is at the heart of every SaaS business, and they shouldn’t be treated like sysadmins. What if you’re like us and you’re processing 100,000+ events per second? When you have a product that processes high volumes of data, customer satisfaction depends on you being aware of the performance of that system at all levels, knowing about performance impact or exceptions immediately, and taking action before they affect customers.
Automation should reach from deployment to monitoring:
- All deployment and adding additional capacity should be one-click
- Monitoring should not only cover system monitors like CPU and disk but also more and more application-specific data points. If you have a big data pipeline, you should have tools capable of measuring what’s coming into each step in the pipeline and how much is going out. If there are any performance issues, you will know about them and be able to take action to recover from them. Furthermore, the information about your pipeline is your foundation for automated monitoring and automated recovery.
- Proper thresholds should be set so that the right people get notified about all exceptions
For example, Loggly does an automated defrag of our ElasticSearch nodes every day. It would only take a person 15 minutes to do manually, but we understand what those 15 minutes could be worth if an urgent matter is demanding our DevOps team’s attention. We also regularly balance the shards when a particular ElasticSearch node gets hot. Our mindset is pretty simple: If someone on our team has been woken up for the same task more than three times, it’s time to automate that task.
Mistake #5: “We don’t need to build an immutable store.”
It’s a tempting shortcut to store only processed customer data. However, if for some reason data corruption occurs, you will then have no way to make a full recovery. Let’s say that an index has an issue, and you can’t recover it. You can’t rebuild if you don’t have the source data. By maintaining a separate store of the clean, unmodified customer data you receive, you’ll always have a way to re-process and recover.
Mistake #6: “Operational metrics are optional; let’s just build them after we get the product out the door.”
If you don’t see your first outage coming and aren’t ready to solve it quickly, your first misstep could be your last because SaaS customers are a fickle lot. Your DevOps team should have one or more dashboards to track the health of the application (using data from your logs, of course :-))
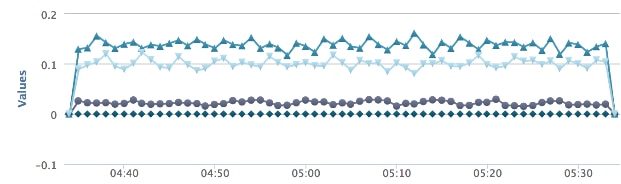
We have instrumented Loggly so that we can measure every step of our customers’ data from collector to mapper to parser to indexing to searchable state – and act when something may be going wrong. For example, the graph below shows a how much data there is in the Loggly queue. If it climbs to a certain threshold, our DevOps team gets alerted.
The best SaaS companies are engineered to be data-driven, and there’s no better place to start than leveraging data in your logs. In fact, we’ve engineered that for you with our cloud-based log management service and made it transparent, starting with our free trial.
PS) We’re growing fast and looking for smart people to help us grow faster. View job openings and join us!
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Manoj Chaudhary

