Why Loggly Chose ElasticSearch Over Solr

When we were in the early stages of developing the Gen2 product we launched last fall, we re-examined every piece of technology in our stack. We started with a clean sheet of paper and looked at every single component of the system. This included the search engine that underpins a lot of our functionality.
Our most common log management use cases revolve around providing full access to individual log events as well as the analytics that give our users a broader picture of what their data is telling them. Addressing these use cases requires:
- A scalable, fault tolerant pipeline for collecting log data. Our team’s recent post on Apache Kafka goes into details about our pipeline; but what I’ll reiterate here is that if you’re going to be feeding a lot of data to any search engine, you need a rock solid pipeline.
- Search technology that can reliably perform near real-time indexing at huge scale while simultaneously handling high search volumes on the same index
In our Gen1 product (2010), we used Solr because in late 2009 it was “months away” from being Cloud aware and supporting NRT (near real-time) search – both of which were crucial features for us. Our first iteration was to take a copy of a branch that contained the first version of Cloud and build on top of that. Due to a variety of factors, the stable version of SolrCloud + NRT wasn’t available until late 2012. In that time, we continued to extend Solr using both plug-ins and by directly modifying the Solr code.
In late 2012, when we started work on Gen2, SolrCloud (4.0) had just been released, and ElasticSearch was at version 0.19.9. Going into the evaluation process, I was a strong proponent for sticking with Solr. By the end of the month or so we spent with both products and in our ElasticSearch vs. Solr performance debate, I had to admit that ElasticSearch was a better choice for us.
As with any technical decision, there were a lot of factors that came into play. In no particular order, here are the most important ones we considered. Bear in mind that these conclusions were valid in late 2012, but things have changed significantly since then.
1) Search Features
Because both ES and Solr are based on Lucene, we were comfortable that either choice would give us the core search features we needed. However, the history of each system and the design focus that was chosen meant that each had strengths and weaknesses that we had to weigh up.
The focus in Solr has historically been on solving hard information retrieval (IR) problems. This was reflected in its API, which exposed more powerful features than ES. ES, conversely, had been built with a focus on elasticity (hence the name) and was a little behind in terms of IR features. In our case, we were not planning on immediately using a lot of the more advanced features. Although Solr held the technical advantage, the fact that ES met our near-term needs made this advantage moot.
2) Search Scalability
We knew we could scale Solr because we had already done it. We knew how it all worked and where some of the limits were. ES was a different story; we had to convince ourselves that it could scale to the levels we needed.
So we spun up large clusters of each system and proceeded to destructively test them both by overloading them with data and by forcibly shutting down nodes to see how the systems behaved under duress. Think Chaos Monkey, where we were the monkeys.
With Solr, one of the biggest problems we found was that a lot of the new features that came out in SolrCloud were very immature, the Overseer/Queue management in particular. We had some real problems with stability running the “out of the box” SolrCloud distribution. In our testing, we saw total lock-ups in the cluster that could only be resolved with a complete reset. ES, on the other hand, sailed through this same testing without any unrecoverable failures. Yes, we could force ES to lose data. However, we understood exactly how that happened and were confident we could engineer our way out of those situations.
3) Plumbing
In building our Gen1 product, we spent a lot of time dealing with Solr “plumbing,” managing where data flowed and how indices and shards were managed and searched. We did this through a combination of plug-ins and direct changes to Solr. Although this is technically challenging and fascinating work, it wasn’t what we wanted to be spending our time on. We wanted to focus on our product differentiation: Surfacing the results and analytics we can get from our engine, to provide better insight for our customers.
ES handily won this contest, primarily because of the ES team’s maniacal focus on elasticity. More specifically:
- The Collections API in Solr was brand new and very primitive, while ES had native, robust, battle-tested index management
- Both had sensible default behavior for shard allocation to cluster nodes, but the routing framework in ES was significantly more powerful and stable than the Collections API
- We debated whether the ES Master/Slave model was a weakness compared to Solr’s distributed model but ultimately decided that the quality of the implementation mattered more than the philosophical approach
4) Performance
Although both ES and Solr are based on Lucene, differences in how each system uses Lucene emerged in our performance tests. In terms of indexing, Solr was a clear winner as seen in the following graph:
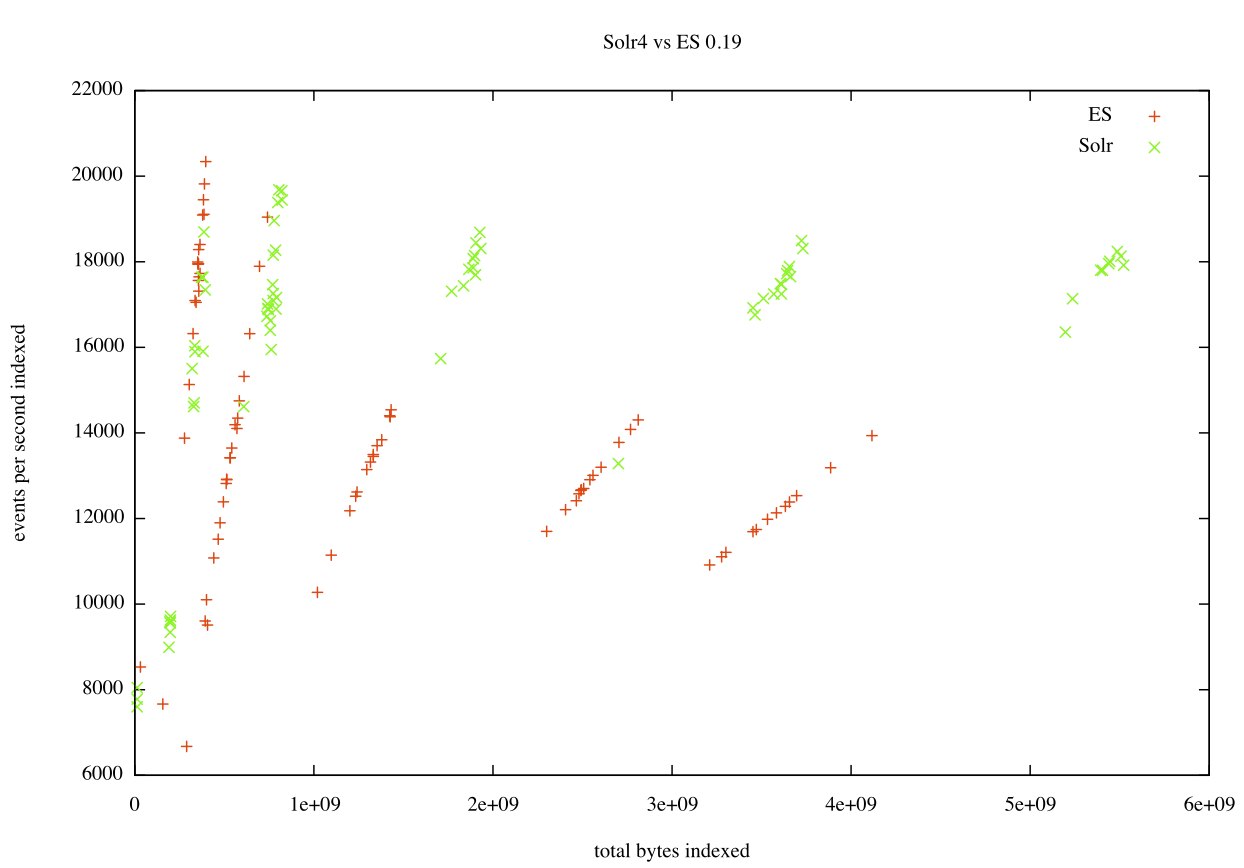
Each data point is a single test where we indexed batches of 8,000 events for a fixed period of time (2, 5, 10, 15 and 20 minutes, left to right). You can see that the results clumped together into fairly clear groups. Solr consistently indexed at about 18,000 eps, while ES started at about the same rate (although with greater variability) then gradually slowed down to around 12,000 eps as the test runs got longer.
Although this looks like a clear win for Solr, a big part of the delta was that Solr was using Lucene 4 while ES was using 3.6. It was hard for us to objectively factor this in, but we knew ES was moving towards Lucene 4 and expected that this gap would close.
Ultimately, performance was pretty much a wash and not a factor in our decision.
5) Community
Both ES and Solr are open source projects, and both had active communities. We discussed the different philosophical models that each used and preferred Solr’s more open model, but were also impressed by the ES team’s stewardship. As far as the size of the community around each project, Solr had the advantage in both size and activity. But ES was growing – and growing fast.
6) Other Decision Factors
We had a laundry list of other things that we liked about each product. Here are a few of those:
- The ES API was elegant and powerful and much more in line with what our front-end team expects from a REST service
- The scan and percolate features in ES were interesting, and we saw lots of potential uses for them both
- Native JSON indexing was supported in both, and this removed yet more code that we’d written in Loggly Gen1
- Automatic typing in ES and dynamic fields in Solr are both very nice ways to avoid managing a constantly evolving input stream
- Native hierarchical/pivot facets in Solr4! Nice!
- ES out of the box experience is much simpler then Solr
- Plug-in support for both is nice, but Solr supported “deeper” plugins
And here are a few of the things we weren’t so crazy about:
- Neither allowed for dynamic changes to the number of shards in an index after creation
- Only single-level facets in ES. Oh well.
- Inconsistencies in ES results depending on whether we used primary or replica shards. In a real-time system, this has the potential to cause real problems.
None of these weighed very heavily in our decision in the end. As each came up for discussion, we made sure we understood the deeper implications so that we knew how much weight to give them.
Our Decision
In the end, our decision for ES came down to a fairly simple bet:
We bet we’d spend less time on plumbing, and more on our product.
We had a side-bet that the areas of relative weakness in ES would be addressed over time.
Both of those bets have paid off, as far as I’m concerned. Even though we had to plumb ES into our pipeline and front-end and our infrastructure team had to implement an Index Manager, that work has been done at a higher level than the work we did in Gen1. This has meant we’ve been able to focus on our product, which, after all, is what start-ups are supposed to do. And it’s what we want our customers to do 🙂
(Did I mention that log management is critical plumbing that you should outsource to an expert like Loggly so you can focus on your core business?)
If we had to make the same search engine choice today, I think it would be a lot harder. Both SolrCloud and ElasticSearch have matured immensely, and the distance between each has narrowed. From my perspective, this can only be a good thing for everyone: The battle between the two systems is driving improvements in both and (possibly even more importantly) in Lucene.
What do you think?
![]()
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Jon Gifford