Using Pending Tasks in Elasticsearch and How to Make Them More Actionable with Loggly
If you have read our first three posts on Elasticsearch, you have probably seen a pattern: Running a large-scale app that heavily uses search is impossible without a bunch of tools in place to tell you what’s going on and when your system needs attention. For us, pending tasks is one of those tools – especially when used in combination with our own log management service.
In Elasticsearch, pending tasks is a queue of cluster-level tasks to be performed: for example, creating an index, updating mapping, initializing a shard, creating shards, or refreshing a mapping etc. ES picks tasks from this queue and executes them. ES has a pending tasks API, which returns any cluster-level task which is not yet executed by ES.
Pending tasks are a good indicator of Elasticsearch health. We use them heavily to diagnose root causes; and you’ll see why they’re so helpful in some of our upcoming posts.
Hopefully you’re familiar with the pending task queue, but if you’re not, you can see what yours looks like by issuing the following command in a terminal on one of your ES nodes:
curl “https://localhost:9200/_cluster/pending_tasks?pretty”
Bringing the Pending Task Queue into Loggly
When we started using ES, we wrote a simple one-line bash command that:
- Made a request to ES to get the pending queue (curl)
- Summarized and serialized the data as JSON (awk)
- Logged that JSON to Loggly (logger)
This let us see how the pending tasks queue behaved over time, which is crucial to understanding why the cluster behaves the way it does. We could easily see when the PT Queue increased, how fast it was increasing, and all of the other awesome things that Loggly helps you spot.
We use pending tasks information daily as a way of checking that everything is normal in our cluster.
Here is an example of what the queue looks like over a 12 hour time period:
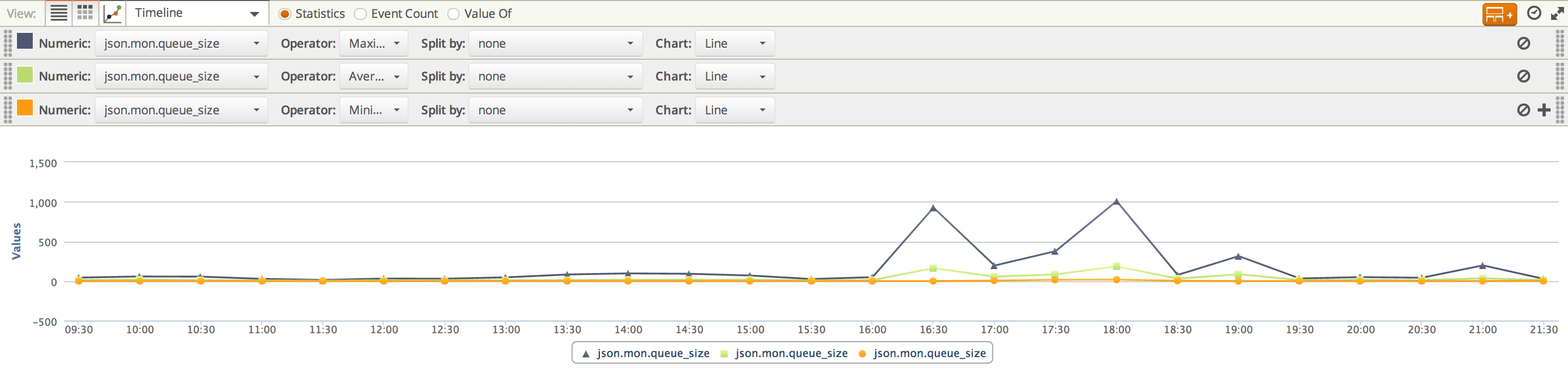
As you can see it was relatively flat for most of the time, but spiked around 16:30 and then stayed fairly high for a few hours. In order to explain this behavior, we need to understand what type of tasks are in the queue. When we do a breakdown by task type, we see this:

As you can see, we have a lot of update-mapping tasks. They’re dominating the graph, and it’s hard to see why we had this spike. Removing the update-mapping tasks from the graph, we get:

This is telling us that in the time-range where we see the uptick in update-mapping tasks, we also see an increase in shard-started tasks. Now the bump makes sense: When a new index is created, we see a bump in shard-started’s, and then (because that index starts out with an empty set of mappings) we also see a jump in update-mappings tasks as data starts to flow into that index.
Why do we see such a bump at 16:30 but not before, when there are also shard-started tasks being handled prior to that? The reason is that the distribution of mappings across our indices is not even – some are “heavy” (i.e. have a lot of mappings) and some are “light” (have fewer mappings). In the case above, we actually created several “heavy” indices simultaneously, and thus incurred a significant increase in the number of updates that needed to be made (starting at 16:30). Over time, as the mapping in each index stabilized, the rate of updates dropped off, and you can see that by about 19:30, we were doing significantly fewer updates.
The graphs above look a little scary! The peaks are pretty high (909 at 16:30, 991 at 18:00), but if we drill down a little to just the time range where we see those spikes, we can see that they’re actually fairly short lived. For 16:30 to 19:30, we see this:
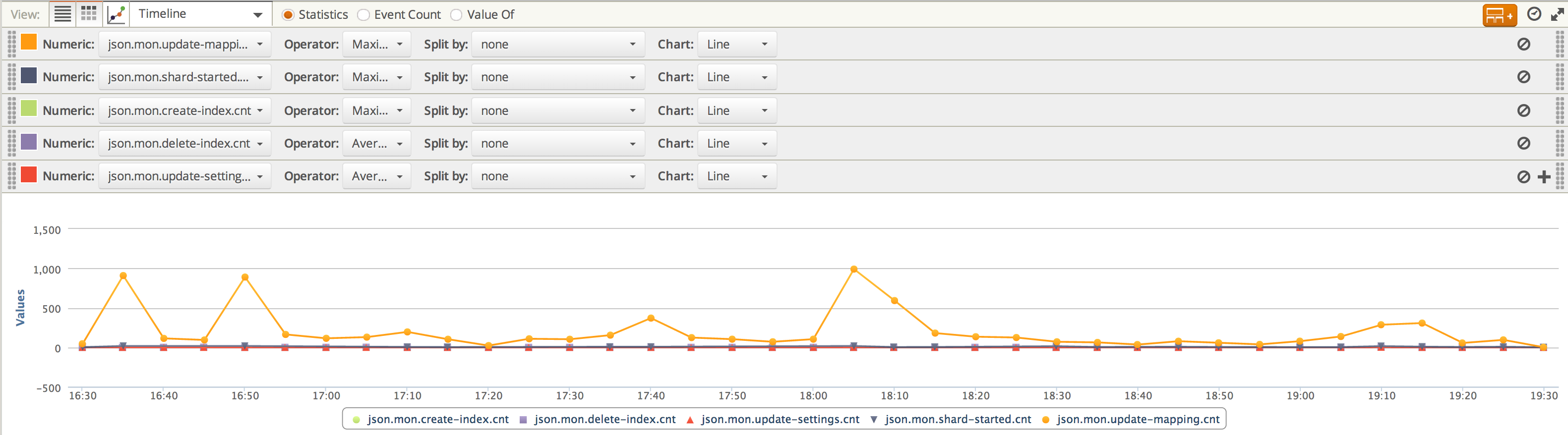
and for 16:30 to 17:00 we see
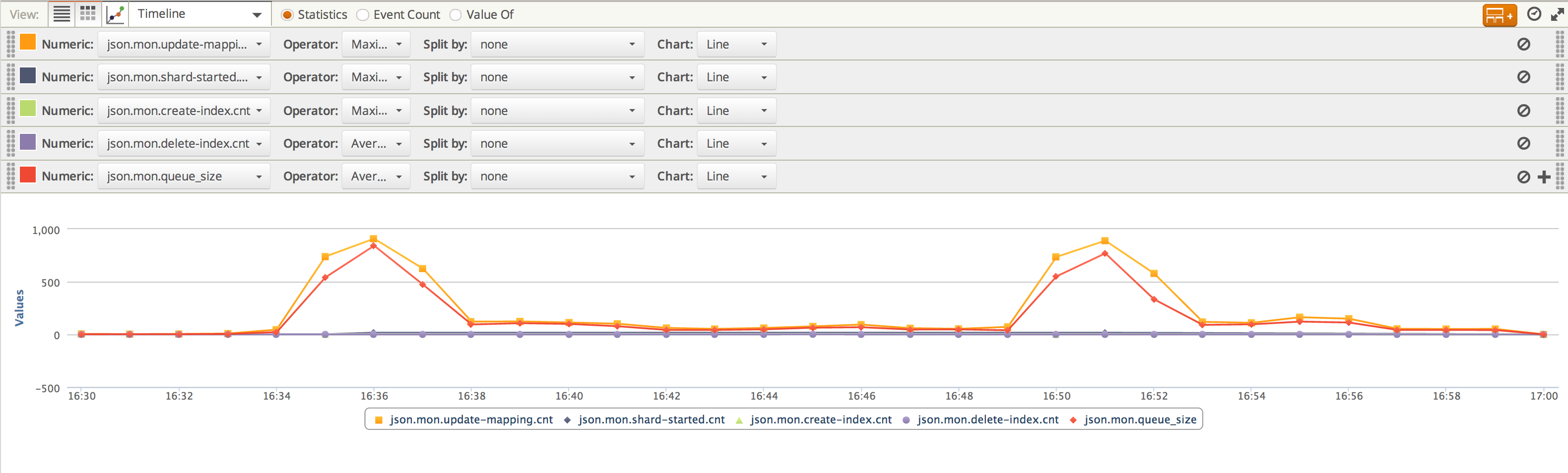
So the spikes lasted only a few minutes each. Even though each one would look a little scary if you just happened to check at the peak time (Pending Tasks Queue almost at 1000!!!!!), the ability to see the patterns that these graphs show means that there is no need to panic. So long as the spike really is a spike, all is well.
Knowing What’s Normal is Key When Things Go Sideways
More generally, having this data available in Loggly makes it possible for us to get a better understanding of what “normal” looks like. And that understanding is really important when things go a little sideways.
When something isn’t working right, we look to the pending task queue for clues to help us diagnose and solve the problem. For example, with a recent replication problem (we’ll link to a future post on this), we could see:
- That shards were being moved around
- How many shards were being moved around
- How long it was taking
With this information, we could predict when the storms we were experiencing would be over. But more importantly, it got us to answers. Stay tuned for our upcoming post, when we’ll share more.
The key takeaway for ES: Take advantage of Elasticsearch pending tasks, and bring the data into a tool like Loggly so that you can realize the full value of what it is telling you.
How We Get the Data into Loggly
The simple one-line cron script we started with has been replaced by a more complex shell script because we wanted to get a little more detail on specific priorities and sources of tasks. Its just one example of a pattern we have found useful here at Loggly.
The basic idea is this: once you have log forwarding enabled on a machine, there is a huge amount of information that you can synthesize as JSON and forward to your Loggly account. You’re really only limited by your own imagination.
You may be asking yourself why you would do this for something like the PT Queue, when its already JSON? Surely you could just add something like this to your crontab:
* * * * * curl https://localhost:9200/_cluster/pending_tasks | logger
The short answer is yes, you could do that, and it would be more useful than doing nothing, but…
Sometimes a summary is more useful than the raw data. In those cases, a simple summarizer script can get you a long way towards understanding what is really happening in your system.
Here is the script we use today:
It depends on the ordering of the JSON elements emitted by ES to work, but it should be pretty self-explanatory other than that if you’re familiar with awk. As an example, here is what this script generates
from the following pending tasks JSON
Here is what our cron looks like:
# pending tasks
* * * * * /opt/loggly/tools/bin/pendingTasks2.sh > /dev/null 2>&1
* * * * * ( sleep 15 ; /opt/loggly/tools/bin/pendingTasks2.sh > /dev/null 2>&1 )
* * * * * ( sleep 30 ; /opt/loggly/tools/bin/pendingTasks2.sh > /dev/null 2>&1 )
* * * * * ( sleep 45 ; /opt/loggly/tools/bin/pendingTasks2.sh > /dev/null 2>&1 )
Yes, we gather PTQ data every 15 seconds.
Check out our tips on how to improve ElasticSearch Performance.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Jon Gifford


