How to Make Logging Even More Responsive By Using a Queueing Server
Here we are in the fourth and final part of the series and, as promised, we’re going to finish up by looking at one final approach to logging before bringing the series to a close. Specifically, we’re going to see how to separate the logging responsibilities from an application by using a queueing server. But, why a queueing server? How will that help?
It’s worth noting that a number of the libraries available for Loggly support both asynchronous logging and have queuing built in. Additionally, rsyslog can queue syslog messages in memory or on disk. Through this functionality, you’ll get similar benefits to implementing a queueing server separately. However, doing it yourself, as we’ll see today, will give you much more fine-grained control and flexibility.
Digital Ocean suggests a number of benefits of integrating a queueing server into our applications; but the key ones for us are these:
- Allowing web servers to respond to requests quickly instead of being forced to perform resource-heavy procedures on the spot
- Letting offline parties fetch data at a later time instead of having it lost permanently
- Introducing fully asynchronous functionality to the backend systems
- Greatly increase reliability and uptime of your application
Consider these four for a moment; they allow us to have our proverbial cake and eat it too. By using a queueing server, the applications which we’re creating can focus more on doing what they’re designed to do, and in the process be more responsive to the needs of their users.
What’s more, they can still incorporate a solid logging infrastructure. Going further, by using a queuing server, instead of performing everything in one application, we can split out logging in to a separate application and scale up and down as the need arises. Log information can be fired off to the queueing server, and a separate process can handle the work of retrieving the information from the server and passing it on to its final destination.
This isn’t to infer that logging places large demands on the resources of an application. It needn’t. A quick tip: when considering whether to split out the concerns of your application, whether they be logging or anything else, make sure that your benchmarks and regular analysis justify doing so. If your application’s performing just fine, then it may not be worth the investment. However, let the numbers decide.
Queueing Servers – In a Nutshell
In essence, here’s how a queueing server works. A queueing server can have multiple queues each holding a different type of information, or message. Messages are added to the queue by processes often referred to as producers and removed from the queue by processes known as consumers.
In our case we’ll have a simple setup with just one queue containing log message information, which we’ll call “log-messages-queue”. The message information will contain enough information to be able to create a log message as we saw in the previous three parts of the series. Consumer processes will pick up the messages from the log queue, and create log entries from them.
Here’s an overview of the message object.
| Item | Description |
| message | The message to be logged |
| priority | The message priority level |
| params | Any extra information, such as formatting, memory observation and so on. |
Now let’s have a bit of a closer look at Beanstalkd. If you’re not familiar with it, according to the official documentation:
Beanstalkd’s a simple, fast work queue. It was developed to improve the response time for the Causes on Facebook application. It has bindings for a wide array of languages, above and beyond the three languages we’ve been considering
There are a range of others available, such as ZeroMQ, RabbitMQ, ActiveMQ, and IronMQ. But I’ve chosen Beanstalkd because it’s one I have some prior experience with.
I’m making the assumption that you either have Beanstalkd setup, or are able to do so quite quickly. If you don’t, you can find installation instructions for most platforms in the official documentation. I’m also using the excellent Beanstalk Console application, which makes interacting with a Beanstalkd server almost painless.
Adding Messages To The Queue
Let’s start by adding messages to the queue. In the code below, we’re using the Pheanstalk library to connect to a local instance of Beanstalkd, listening on port 11300. We’re implicitly creating a queue, called log-messages–queue, and adding a JSON encoded message payload to it, which we covered earlier.
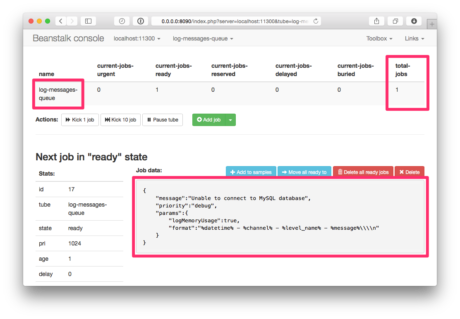
Assuming that we’d already run the code above, here’s what it would look like in Beanstalkd. You can see that the queue has been created and it contains one job. The contents of the job are visible at the bottom, so you can see that the information has been stored successfully.
Retrieving Messages From The Queue
Now that we have a message in the queue, let’s see how we retrieve and process it. The code below, though a bit of a long example, makes use of the Pheanstalk code from the first example and the Monolog library from my previous blog post.
First we reference all of the classes we’ll need. We then create a function which will Initialize a log object for us, based on the contents of the message retrieved from the queue. As with the example in Part Three, we’re using a stream and Loggly handler.
If the message data requires memory usage to be recorded the two usage processors are added to the log object. If a format is supplied, then the stream handler is given a formatter, initialized with the format string. With all that done, the log object is returned.
Then, as in the previous example, we:
- Make a connection to the Beanstalkd server
- Set up a listener which will poll the queue and retrieve jobs as they’re added, logging them based on the information in the message and deleting them afterwards.
In production, you may not quite do it like this; but it serves as a simple example of how you could. Through following this kind of approach, you can now offload the majority of the processing required to log messages to a separate process, allowing your application to do what it does best.
You Should Participate Too
Before I finish up, I want to encourage you to get involved. I’ve talked a lot about the functionality of existing languages and third-party libraries. But what if your language doesn’t fit the bill? What if it’s missing a feature which you’ve seen present in the ones we’ve covered?
If there’s a logging library you use, or if your favorite language doesn’t have a feature which you need, or which you believe should be there, or it has a bug — get involved! If you’re not sure how, here are three suggestions:
- Submit a bug report to the project maintainers
- Develop a patch and submit a pull request
- Create documentation if it’s lacking
It’s easy to complain, but no one has unlimited resources, whether because of time or money. I strongly encourage you to get involved and make the situation better, both for yourself and for everyone else. Yes, it is easier said than done; not all of us are developers. But I want to encourage you to do what you can.
Lastly, don’t feel that you need to just use the libraries and languages I’ve presented. If you know of better ones, and that’s where the experience of you and your team lies, then by all means use it. And I encourage you to share your experiences by commenting on this blog post.
Summary
And here we are at the end of the series, so let’s take moment to recap what we’ve covered. In Part One, we looked at four key considerations for logging in PHP, Python, and Ruby, as well as the basics of logging in each language.
In Part Two we got more hands-on with code, looking at some of the sophisticated features on offer; such as handlers, formatters, and priority levels. In Part Three we looked at three further questions which helped to further round out our approach to logging, using the excellent Monolog library to provide working examples.
Finally, here in Part Four, we’ve finished up by looking at the asynchronous use of queuing servers, to allow us to perform all manner of logging, yet maintain low overhead and high responsiveness on our applications.
I hope you’ve enjoyed it and gotten a lot out of it. All the best in your logging efforts. If you have any questions, tweet me (@settermjd) or the good folks at Loggly (@Loggly).
Keep Reading This Series
« PART 3: How to Solve Privacy, Security and Performance In Logging
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Matthew Setter