Taming the wolves behind monitoring alerts
Almost 2,500 years ago, an old man named Aesop travelled across villages near the picturesque hills of Greece. Along the way, he shared short stories he had learned from other lands. One such story was that of the shepherd boy who watched a flock of sheep near a village. That boy used to lure innocent villagers many times by crying out, “Wolf! Wolf!” When the villagers would come to help him, he would laugh at their folly. However, one day the wolf did come and when the boy called for help, no one paid any heed to his cries. The wolf destroyed the boy’s flock of sheep.
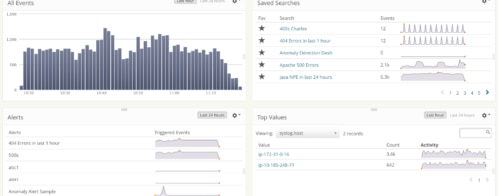
You may wonder what this story has to do with logging. Well, logs are a huge cauldron of noise, and alerting is a way for us to filter out the noise and reveal what really matters. Creating and managing alerts, however, is not easy. You can’t be sure that the alerts will never miss anything or repeatedly “cry wolf.” In the 2016-17 VictorOps State of On-Call survey of 800 on-call professionals, while 53% reported alert noise as a problem, 61% stated that alert fatigue is also an issue. So how do you find the right balance?
Be Agile, Be Bold
As a product manager, I have set up alerts to inform me when some old or new feature stops working. On several occasions, I have accidentally flooded my inbox with alert notifications while creating and fine-tuning my alert rules. If that happens to you too, just turn off the alert, clear all notifications, and turn the alert back on after updating its conditions. Loggly makes it easy for you to suppress (think: snooze) or disable the alert in a few clicks from the UI itself.
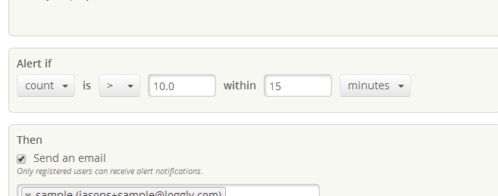
Don’t be afraid to experiment and refine your alerts based on what you learn from the data! You might not be able to know every meaningful alert pattern in advance, so identifying the right events and finding the right threshold is not always an easy task. But if you don’t analyze your logs and look for what’s going on, you’ll never be able to detect that meaningful activity and set helpful alerts.
Be Comprehensive, Be Creative
As a business, you want to be prepared for any scenario. You would rather be woken up by a false positive alert in the middle of the night instead of being at the receiving end of furious emails and tweets from your high-value customers early morning. If you are not getting enough alerts, then you have not covered enough cases. If you are receiving too many alerts, then you need to prioritize and assign appropriate notification channels. One way to do this is to ask questions like, “Does this need an alert or can I have this on a dashboard?” While each team must ultimately choose which items and thresholds receive alerts, we recommend setting up alerts for business-critical items and monitoring the remaining non-critical items through dashboards.
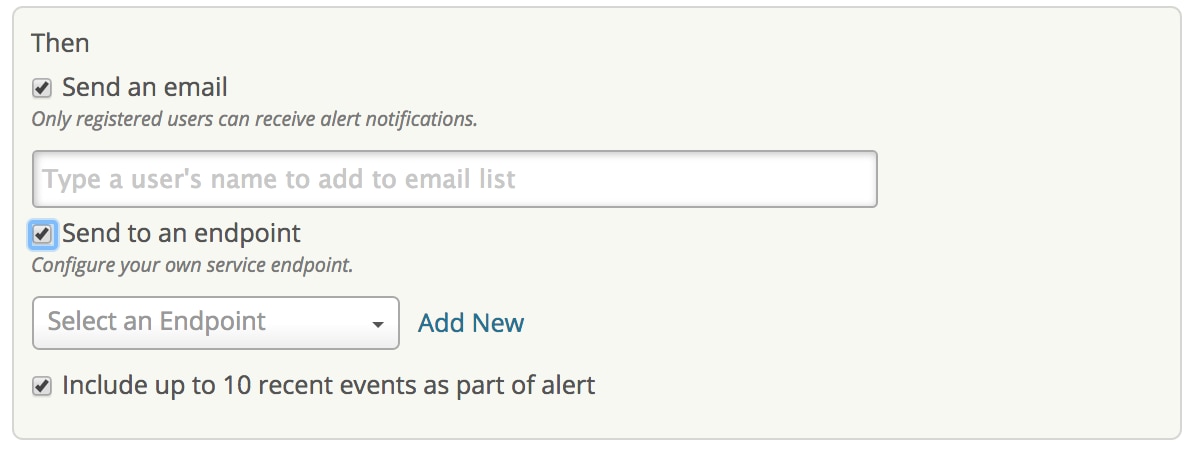
In the VictorOps survey, while 89% reported using a group chat tool, 80% said they are doing some form of ChatOps (a conversation-driven development). Loggly makes it easy for you to set up and send notifications to different endpoints such as Slack, HipChat, PagerDuty, and VictorOps. You also have the option to send notifications to a generic HTTP endpoint. For each alert you set up, you may also want to ask yourself, “Does this really need an email or PagerDuty notification to my team members, or can I direct this to a less invasive Slack/HipChat channel?” If you choose any endpoint such as Slack and HipChat, we recommend that you manage the room notification settings inside Slack and HipChat so that users don’t miss out on important alerts.
Be Earnest, Be Open
Based on our own experience internally, we can easily say the most valuable alerts are actionable and include as much context as possible. A quick and simple best practice here is to give meaningful names and descriptions to your alerts in Loggly. You would be doing yourself a disservice by creating alerts that do not include as much detail as needed to resolve the issue. In the same VictorOps survey, while 39% said that lack of remediation information is a problem, 32% highlighted inefficient communication as another core problem.
So one of the things you must do, if you haven’t already, is discuss and review all your alerts as a team, so that everyone knows how different types of alerts must be prioritized — or, to come back to Aesop’s story of the shepherd and the wolf, when they need to take immediate action to prevent damage. Prepare a collaboration document and clearly capture information that identifies:
- The alert conditions,
- Who created the alert,
- The business and operational impact of the alert, and most importantly,
- What must be done to resolve the alert condition.
If you look at alerts as a collaborative process, you will make it easy to reduce the number of noisy alerts and troubleshoot quickly.
Be Proactive
Logs are the most valuable tool during a firefight and Loggly alerts are a great way to stay on top of critical issues. Create Loggly alerts for effective web server, application, mobile app, database, and network monitoring that proactively surfaces the wolves lurking around your software. Alerts are available to our customers in all paid tiers. If you haven’t tried Loggly yet, you have one more reason to get started now!
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Pranay Kamat Pranay Kamat is Senior Product Manager at Loggly. His previous experiences include designing user interfaces, APIs, and data migration tools for Oracle and Accela. He has an MBA from The University of Texas at Austin and Master's degree in Computer Science from Cornell University.