Why Loggly chose Amazon Route 53 over Elastic Load Balancing
The key function of our log management service is to process massive amounts of log data from a wide variety of sources, parsing and indexing it to make it ready for analysis and monitoring in near real-time. The first entry point to Loggly’s big data ingestion pipeline is what we call our collectors. (You can learn more about the whole pipeline in this recent post.)
Loggly Collectors Perform One Key Task: Log Ingestion
The Loggly collectors ingest all of the incoming streams of log data from our customers and move that data down our log management pipeline for processing. They are written in C++ and are designed to support the TCP, UDP, HTTP, HTTPS, and TCP over SSL communication protocols. The collectors have two purposes:
- To work at network line speed
- To not drop any data, ever
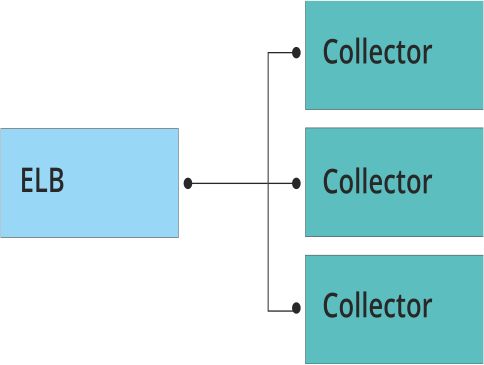
The collectors need to be able to collect logs no matter how fast our customers throw them at us. They are designed to run completely segregated from rest of the Loggly stack. This architecture allow us to leverage multiple regions and multiple Availability Zones (AZs) from AWS.
Log Management Scalability Requires a Way to Balance Traffic Across Collectors
Throughout our architecture, we have made scalability a top priority. Since the collectors are the first step in our pipeline, we needed to find something to sit in front of them that would:
- Balance the load across collectors
- Offer fault tolerance, allowing us to continue ingesting data if one of the collectors dies or is experiencing issues
- Scale horizontally with the growth in our log volumes
Given that our infrastructure runs on Amazon EC2, we looked first to AWS Elastic Load Balancing (ELB). In this post, I will discuss some of the limitations we found with ELB and explain why Amazon Route 53 DNS works better for our log management use cases.
ELB Operates on a Simple Concept
As the name suggests, ELB is elastic; it can balance the load without exposing what is running behind it. The way I like to think about ELB is that it’s like a parking attendant: As a car comes to the parking gate, it routes them to the floor with fewer cars. Similarly, ELB routes the traffic to the nodes sitting behind it. ELB shares another characteristic with a parking attendant: It is relatively expensive because it has to stop each and every car coming into the parking lot and provide it with information about where to go.
Increasing Log Volumes Led to Latency Issues with ELB
We started our journey with ELB deployed in front of our collectors as shown in the diagram below. However, we started hitting latency issues in streaming traffic to the collectors when volumes got into the tens of thousands of events per second. We built our collector to be as efficient as possible, so these latency issues were essentially defeating its purpose.
Issue #1: ELB doesn’t allow forwarding on port 514.
One of Loggly’s key competitive advantages is that we don’t require our customers to install agents on their local machines. We ingest logs via syslog, which has been shipped with Linux- and Unix-based systems for ages. We always want to make sure we are compliant with open standards. According to the syslog RFC 5426, syslog receivers should listen on port 514, so our load balancer should able to listen and forward port 514. However, ELB doesn’t have the ability to forward on 514. Its acceptable protocols are HTTP, HTTPS, TCP and TCP over SSL and ports 25, 80, 443, 465, 587, and 1024-65535.
Issue #2: ELB doesn’t support forwarding via UDP.
According to RFC, the syslog receiver should support the UDP protocol. Loggly does not recommend that our customers send data on UDP because it is not a guaranteed delivery protocol, but we need to be able to support it in order to be fully compliant with syslog. Furthermore, some customers do have legitimate use cases for sending data on UDP. Thus our second hiccup with ELB: UDP is not supported. (ELB does support load balancing only on HTTP, HTTPS, TCP, and TCP over SSL.)
Issue #3: Bursts in log event traffic can hit ELB performance limits.
One of the biggest challenges with a SaaS service—especially a log management service—is that customer traffic patterns are never entirely predictable. (Read more about this in my post on six critical SaaS engineering mistakes you want to avoid.) Our incoming traffic varies a lot, and we can have sustained bursts lasting hours when customers are experiencing operational problems that generate lots of logs (Or when they mis-configure their logging, but that’s another story). Of course, these high-traffic periods are the times when we need load balancing the most.
So here’s where our critical issue with ELB came into play: When we ran simulations of log event bursts, we started to reach its performance limits. And we simply can’t afford to have latency on our traffic hitting the collector.
Here are some ELB performance numbers from testing by Rightscale.

It’s important to note, however, that Amazon provides limited visibility into exactly how ELB is performing. Under the covers, AWS scales an ELB instance up or down based on traffic patterns, and AWS proprietary algorithms determine how large the ELB instance should be. If the ELB instance doesn’t fit with your traffic patterns, you will get increased latency. AWS CloudWatch does make some metrics available, specifically HTTPCode_ELB_5XX. But this metric does not clearly indicate whether latency is due to ELB or to your server.
Amazon Route 53 Aligned Better with Log Management Use Cases and Requirements for Performance, Fault Tolerance, and Scalability
Once we discovered ELB’s limitations, we looked for alternatives and settled on Amazon Route 53 Domain Name System (DNS).
Amazon Route 53 DNS Round Robin Was a Win
If you’ve ever used the Internet, you’ve used the Domain Name System, or DNS, whether you realize it or not. A DNS is a service whose main job is to convert a user friendly domain name like “loggly.com” into an Internet Protocol (IP) address like 198.192.168.29 that computers use to identify each other on the network. In Amazon EC2, Amazon Route 53 is an “authoritative DNS” system, meaning that it provides an update mechanism that developers use to manage their public DNS names. It then answers DNS queries, translating domain names into IP address so computers can communicate with each other.
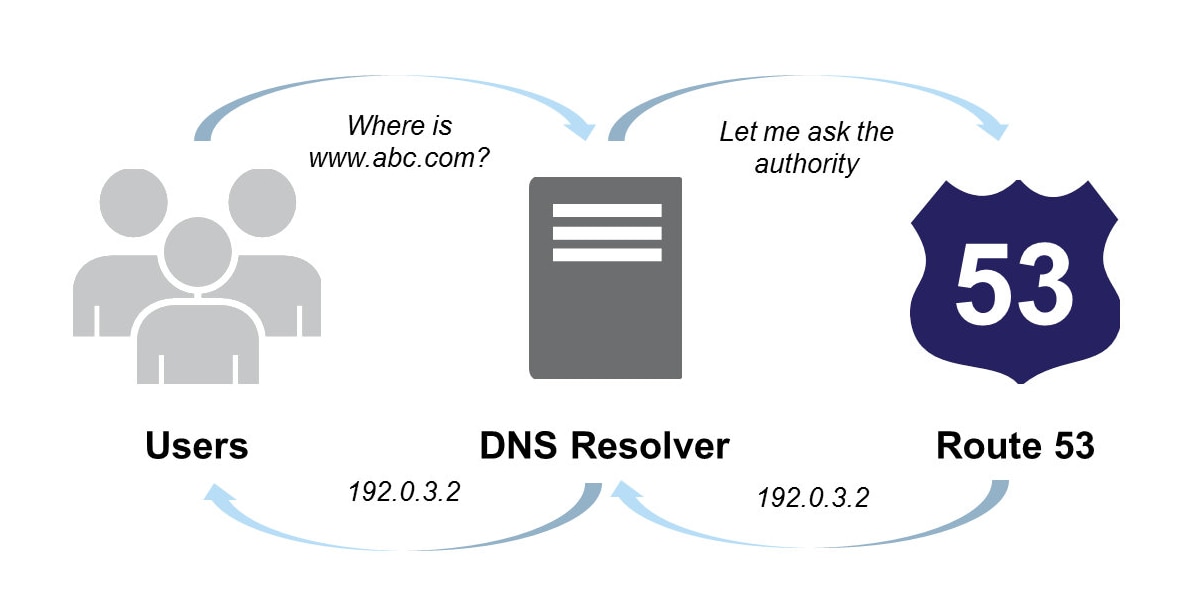
There are bunch of of routing mechanisms available with Route 53 DNS, as pointed out in its Developer Guide. Round robin is pretty basic load balancing, but it works well for us from an efficiency standpoint. We use weighted routing with equal weighting, which converts it into simple round robin. When a request is sent through DNS Route 53, it gets to the socket of the server sitting behind it right away, so there is no performance impact in collecting the log events.
Failover Checks Provide Fault Tolerance
Since the key goal for the collector is to implement our “no logs left behind” policy, we take advantage of Route 53 failover health checks. If there is an issue with a collector, Route 53 automatically takes it out of the service; our customers won’t see any impact. When we have to add more collectors, we can do so seamlessly. When a collector goes out of service, it goes out of the DNS rotation. We have collectors provisioned behind the DNS in different AZs. Route 53 routing works across the AZ, so whenever there is an outage in one AZ, data will go to the collectors running in different AZs. Thus we gain the ability to scale across zones, and we’re protected from faults in case we hit issues with an AZ.
Route 53 DNS Optimizes Inbound Traffic
Route 53 detects and resolves our collector IP so data can go straight to collectors without any overhead. It leverages the high-performance collector software we have built and doesn’t have to go through load balancing latencies.
No Pre-Warmup Required with Route 53
Finally, Route 53 is more graceful about handing the unpredictable log event bursts that start coming with no notice.
Summary: Route 53 Makes Good Sense for Application with High, Unpredictable Loads
Route 53 turned out to be the best way for Loggly to take advantage of our high-performance collectors given our huge log volumes, unpredictable variations, and constant growth in our business. It aligns with the collectors’ core purposes: To collect data at network line speed with zero loss, and it allows us to benefit from the elasticity of all of the AWS services we use at Loggly.
Now that you’ve learned how and why we selected Amazon Route 53 over Elastic load balancing, signup for a FREE no-credit card required Loggly Trial and view performance, system behavior, and unusual activity across the stack. Monitor key resources and metrics and eliminate issues before they affect users.
>> Signup Now for a Free Loggly Trial
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Manoj Chaudhary